
- 了解序列化的意义
- 如何实现一个序列化操作
- 序列化的高阶认识
- 常见的序列化技术及应用
- Protobuf实现原理分析
- 序列化框架的选型
了解序列化的意义
我们非常的考虑系统性能的时候,就要考虑到序列化。
序列化在我们系统架构里边处于非常底层的位置。我们平时不会去关心,我们使用的是什么序列化。后者说我们用的一些RPC框架它是怎么去做的。
远程通信需要用到序列化。
序列化和反序列化是我们几乎每天面临的问题,
项目之间的调用都需要序列化。是我们必须要掌握的东西。
如果想把java对象传输给其他的进程。
JVM内部有一个内部的对象,需要传输。
对象的传输怎么去做
RPC做远程传输,不可能只传输字。
节流,还需要一些java对象。
分布式架构,大数据量系统,我们对序列化的性能对我们的系统的性能影响去关注。想要提升整体的性能。
Socket传输一个流,可以简单的传输
当我们要传输List/Object等java对象时,怎么办?
Java中允许在内存中创建一些可复用的java对象,只有在JVM在运行时对象才会存在,然后JVM的生命周期限制了对象的生命周期。
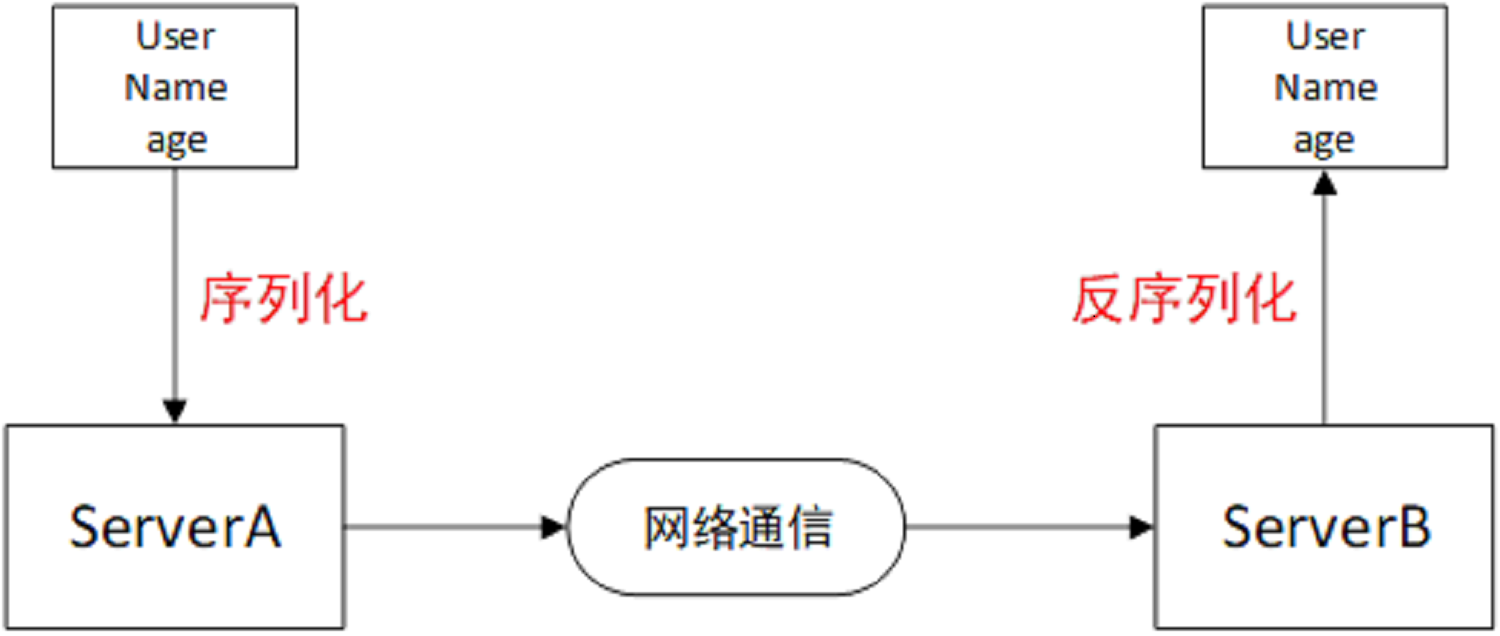
发送端 序列化 把对象的状态信息可存储可传输的形式的数据
接收端 反序列化 反过来。
使用tomcat时,把session放在内存中,如果用户比较多的话,比如说10万,100万,假设,那我们会把session数据放在磁盘上,然后用的时候在反序列化。
远程传输
状态信息存储到磁盘上
序列化带来的挑战
我们希望序列化出来的数据越小越好,越小就越节省带宽,序列化本身会占用我们的内存和资源,
序列化,序列化快,慢,然后 序列化出来的字节流的大小。
Java实现序列化:serialization
Serialization
数据比较大语言限制(跨语言跨平台)Xml(soap)(WebService里面用的很多,比java生成出来的二进制的序列化方式更加容易理解)
JSON
简单文本格式的,基于restful风格的API逐步取代XML
Spring 4 以后自带基于jackJson了自动转化json的功能,
但是JSON,占用的空间也很大,而且性能也相对比较低。
跟用户打交道时,提升效率。
Protobufs messagepack
IDEA设置生成SerialVersionUID
- setting
- Editor
- Inspections
- serializable class without serialVersinUid : ✔️
- Inspections
- Editor
@Data
public class User extends superClass implements Serializable {
private static final long serialVersionUID = -281884127299001746L;
// private static final long serialVersionUID = -1L;
private static Integer b = 5;
private Integer age;
private String name;
}@Data
public class User extends superClass implements Serializable {
private static final long serialVersionUID = -281884127299001746L;
// private static final long serialVersionUID = -1L;
private static Integer b = 5;
private Integer age;
private String name;
}serialVersionUID作用
版本的UID
- 判断类是否一样的,
默认的根据calss文件,生成对应的64位的hash字段。(我们看不到)
编译的时候生成的
java.io.invalidCalssException: com.gupao.User. class compatible: : seriVersionUid : -3493499349L. local class serialVersionUid = -3
at java................java.io.invalidCalssException: com.gupao.User. class compatible: : seriVersionUid : -3493499349L. local class serialVersionUid = -3
at java................面试题:
serialVersionUID不一致
- 假如说序列化与反序列化的serialVersionUID 不一致,会报invalidCalssException错误。
假设两个serialVersionUID一致,
序列化的类是四个字段,反序列化的类是三个字段,两个serialVersionUID一样,
序列化的类是四个字段,序列化,然后反序列化传输进去类三个字段,然后序列化不报错,
只不过是三个字段
三个字段序列化, 反序列化传出进 去类四个字段,序列化不报错,为空
静态变量的序列化
在类中定义一个静态变量。
Java序列化存储类的瞬时状态。
静态变量不参与序列化。
transient
Transient表示不会被序列化。
父子类关系
序列化的对象必须实现序列化,
子类实现序列化,父类不实现序列化,不能够被序列化
父类实现了序列化,子类不实现序列化也可以序列化。
可以自己写一个writeOjbect
手写序列化,反序列化 绕过 transient 实现序列化。
手动的写到流里边。
序列化两次
一个序列化的文件大小,
对一个对象在同一个流里边输出两次,
在同一个流管道里输出两次并不会输出两次
第二次输出的是上一个对象的引用
加了5个字节,
指向同一个对象。
克隆
序列化可以实现克隆
Clonable 克隆接口,浅克隆
浅克隆
浅克隆,只克隆这个对象的所有的值,和他这个对象本身,只是一个引用。只是一个引用,并不是一个新的对象。引用的对象不会被复制。
它只是克隆当前这个对象本身可这个对象对应的值,但是这个对象里边成员变量里边的对象所指向的引用,它不会再去克隆。
public class CloneDemo {
public static void main(String[] args) throws CloneNotSupportedException,
IOException, ClassNotFoundException {
Email email = new Email();
email.setContent("今天去钓鱼");
Person p1 = new Person("A");
p1.setEmail(email);
//Person p2 = p1.clone();
Person p2 = p1.deepClone();
p2.setName("B");
p2.getEmail().setContent("今天去打架");
System.out.println(p1);
System.out.println(p2);
}
}public class CloneDemo {
public static void main(String[] args) throws CloneNotSupportedException,
IOException, ClassNotFoundException {
Email email = new Email();
email.setContent("今天去钓鱼");
Person p1 = new Person("A");
p1.setEmail(email);
//Person p2 = p1.clone();
Person p2 = p1.deepClone();
p2.setName("B");
p2.getEmail().setContent("今天去打架");
System.out.println(p1);
System.out.println(p2);
}
}结果
Person(name=A, email=Email(content=今天去打架))
Person(name=B, email=Email(content=今天去打架))Person(name=A, email=Email(content=今天去打架))
Person(name=B, email=Email(content=今天去打架))深克隆。
// 用序列化实现深度克隆
// 手写深度克隆
public class xxxxx Implents serialable{
// 序列化,方法
// 反序列化 方法
}// 用序列化实现深度克隆
// 手写深度克隆
public class xxxxx Implents serialable{
// 序列化,方法
// 反序列化 方法
}深度克隆以后的结果
Person(name=A, email=Email(content=今天去钓鱼))
Person(name=B, email=Email(content=今天去打架))Person(name=A, email=Email(content=今天去钓鱼))
Person(name=B, email=Email(content=今天去打架))传输对象,序列化

常见的序列化技术
考虑因素
序列化结果的数据大小序列化占用CPU,内存 性能序列化的复杂度。实现起来是否复杂,学习成本
XML形式,
序列化,可读性非常高,效率低,数据量大。
应用:webService 中的soap (http+xml)传输的形式
性能要求很高的时候不会选用XML技术。
<dependency>
<groupId>com.thoughtworks.xstream</groupId>
<artifactId>xstream</artifactId>
<version>1.4.9</version>
</dependency><dependency>
<groupId>com.thoughtworks.xstream</groupId>
<artifactId>xstream</artifactId>
<version>1.4.9</version>
</dependency>基于 OXMapping 的一个实现方法
基于JSON实现序列化
Jackson spring 默认使用 比 `fastjson` 快 比GSON的性能要好Fastjson 据说最快 不太稳定GSON 谷歌的GSON
Jackson、GSON 比 fastjson 的稳定性要好
- Hession 序列化 hession2
- Dubbo默认使用hession 对 hession实现了一个优化,生成的流的时候做了一个压缩。Hession2实现了多个序列化的选择,
所有序列化生成的数据格式不一样
- hession2 对 hession做了一个优化,他的性能也是不错的。
Dobbo提供的序列化
ConpactedJavaSerializatioin压缩的java序列化DubboSerializationFastJsonSerializationHession2SerializationJavaSerializationJsonSerializationNativeJavaSerializationKyio 和 protobuf 都不能选择
Protobuf序列化框架
优点
- 谷歌开源
- 独立语言、独立平台
- (基于Java,基于C,基于C++,基于pathon,它可以去做不同平台的交互)
- 纯粹的基于表示层的协议,它可以和各种传输层协议一起使用。
- 压缩以后空间开销小,性能比较好
- 性能要求高的话,需要用protobuf
- 解析性能比较高
缺点
Protobuf 学习成本比较高,使用起来比较麻烦。
Github上有独立的编译器,
下载编译器编写独立的proto文件(自己的语法)编译(通过编译器编译成java版本)
下载:
- https://github.com/google/protobuf
- release
protoc-3.6.0-win32.zip
创建文本 `user.proto`
定一个一个proto文件,
Syntax = “proto2”;
Package com.gupaoedu.serial;
Option java_package=”com.gupaoedu.serial”
Option java_outer_classname=”com.gupaoedu.serial”Syntax = “proto2”;
Package com.gupaoedu.serial;
Option java_package=”com.gupaoedu.serial”
Option java_outer_classname=”com.gupaoedu.serial”文件格式
编译命令
- Shirft + 右键 打开 powerShell
Fluent风格,实现序列化
粘贴进去.java文件
public class protoBufDemo {
public static void main(String[] args) throws InvalidProtocolBufferException {
// fluent 风格
UserProto .User user = UserProto.User.newBuilder().setName("Darian").setAge(18).build();
ByteString bytes = user.toByteString();
System.out.println(bytes);
UserProto.User nUser = UserProto.User.parseFrom(bytes);
System.out.println(nUser);
}
}public class protoBufDemo {
public static void main(String[] args) throws InvalidProtocolBufferException {
// fluent 风格
UserProto .User user = UserProto.User.newBuilder().setName("Darian").setAge(18).build();
ByteString bytes = user.toByteString();
System.out.println(bytes);
UserProto.User nUser = UserProto.User.parseFrom(bytes);
System.out.println(nUser);
}
}<ByteString@20sdfsfd2 size=10>
name: "darian"
age: 18<ByteString@20sdfsfd2 size=10>
name: "darian"
age: 18Protobuf 原理解析
Protobuf 为什么序列化的字节数那么小,
利用了位运算
BitMap/BitSet
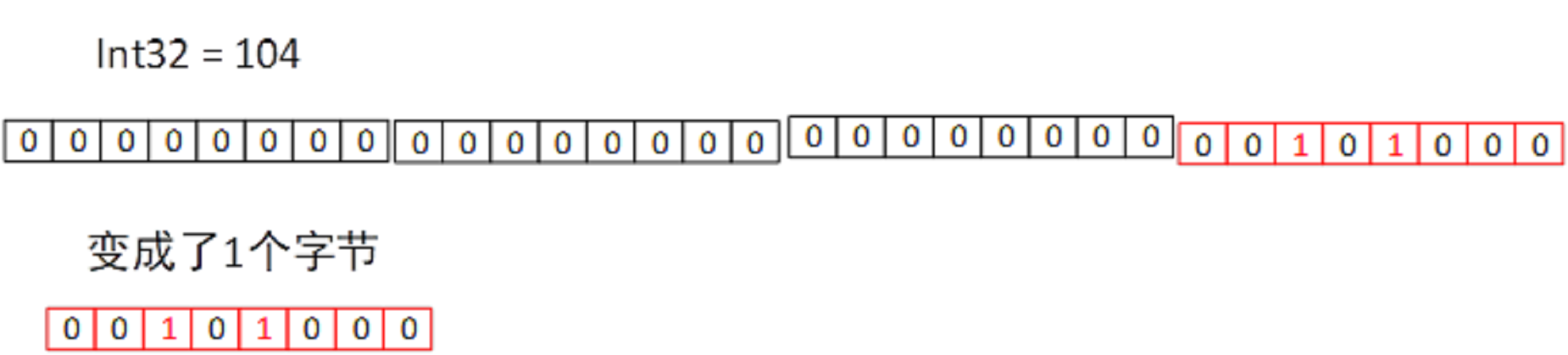
一个int 4个字节,一个字节8个byte位。

Varint做编码
T-L-V做存储
Protobuf存储占用的空间很小而且你存的数越小,它占用的空间数越小。
数字和字符串都要转化成编码 去存储。
Int 32 = 296 【23个0】 100101000
前边的23个0全部是浪费的。
Varint有自己的编码规范,
第一步:Varint从末尾开始选取7位

负数存储很麻烦
根据原始的数生成一个二进制,去做一个反转,反转以后再取一个异或运算,所以最后生成的结果会远远大于它本身。
按照这种存储,负数反而更大。
负数是(zigzag)

Int 32 = -2 00000010
11111101
11111110
左移一位右边补0
右移31位,左边补1
111111100 ^ 11111111
00000011 (zigzag)
Protobuf存储

Int 存的是32个数字
Tag、Length、Value
存value时,
首位不懂剩余位减1取反
Field number<<3 | wire type
Wire_type 0 int32 int64
Wire_type 1 18个字节 double
Thrift/Avro/Kryo/messagepack/FST
序列化选型的因素
序列化的开销,序列化结果大小,序列化的性能,算法,计算规则,计算的耗时。跨语言跨平台,兼容性学习成本,这门技术的学习成本。
二进制复杂对象的存储