
了解zookeeper及zookeeper的设计猜想
Zookeeper集群角色
深入分析ZAB协议
从源码层面分析leader选举的实现过程
关于zookeeper的数据存储
回顾内容
zookeeper集群安装(myid/zoo.cfg)zookeeper的数据模型(znode)节点的特性
(持久化、临时节点、有序节点、同级节点必须唯一、临时节点不能存在子节点)
节点的status信息简单的了解了watcher机制。Zookeeper的应用场景
Zookeeper的由来
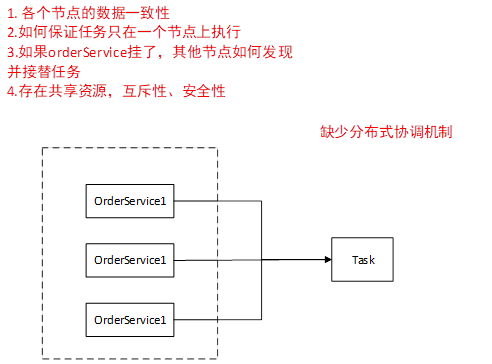
分布式架构下面临的问题
我们有一个orderservice
我们对这样的一个模块建立一个集群,我们对同一应用去做拷贝,相同于是部署了三份一模一样的 这些模块中运行一个 Task 叫任务
因为我们是一个集群,所以我么你每一个节点都有权限去执行这个任务,
我们每一个服务都会有一个配置文件,application.properties,配置文件中会配置一些数据库的信息,连接信息,服务地址信息等等,我们可能有些东西是需要动态变更的,这是一个背景,然后这些数据需要进行调整的话,因为现在是一个集群,所以现在必须在同一时刻,对这些数据进行一个更新,但是如果你是保存在配置文件里边的话,你怎么保证各个节点的数据保持一致。
我们现在一个server执行一个任务,假如说 ,这个任务在server1上执行,怎么控制这个任务只在server1上执行。假如说我们有一个定时任务解析文件去入库,我们怎么只让其中一台机子去解析这个文件,其他机子不解析这个文件。因为如果三台机子都做这个任务的话,意味着数据要做三次。
如果你有一个手段让一个任务只在一个server上执行,如果其中一个服务挂掉了以后,其他节点怎么知道它挂掉了,去重新接替任务。
我们如果说存在一个共享资源,集群对每一个节点都是公平的,所以存在某一个时刻,很多个服务去访问同一个文件。再访问的时候怎么去保证互斥性,就想多线程里边,多个线程同时访问同一块资源,如果保证线程资源的安全性。
集中式到分布式架构发展带来的问题:
各个数据节点的数据一致怎么保证任务只在一个节点上执行。如果某个节点挂了,其他结点如果发现并接替任务。存在共享资源。互斥性、安全性
总结一下,就是缺少一个分布式的协调机制。
分布式协调做的比较好的一个是
谷歌的chubbyApache的zookeeper
谷歌的chubby是一个分布式锁的东西,
解决分布式锁,master选举,的一些相关的服务
雅虎公司内部很多模块,它需要依赖一个系统,去对里边的分布式系统去做一个协调,然而Google的chubby不开源。 所以雅虎基于chubby的思想开发了zookeeper,捐献给Apache,所以现在我们下载的zookeeper是从Apache上下载下来的。
这就是我们为什么要用zookeeper机制的原因 。
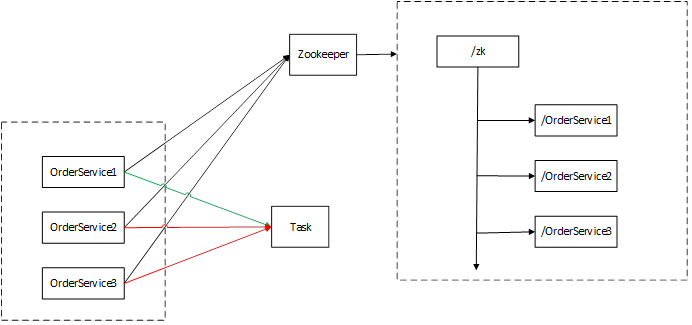
Zookeeper,是一个文件结构的树形结构的数据存储,我们基于zookeeper本身的数据结构和它的节点特性,我们可以利用它去实现一个,互斥的访问
那么我们就需要先去注册一个结点,因为zookeeper节点是一个树形结构
我们吧zookeeper中最小的那个节点有优先权,第一个服务去执行,后边的两个就不让它去执行。我们利用zookeeper起到对我们相关服务节点协调的控制。
如果我们的zookeeper作为我们整个系统的服务协调中心的话,那么zookeeper就会成为一个瓶颈,而zookeeper目标是提供一个高性能,高可用的,有严格访问顺序的控制能力(表示写操作的顺序)分布式协调服务。
初衷
基于zookeeper的初衷,我们要解决zookeeper的性能问题。
还有它本身的可用性,我们不能让它本身成为一个单点,如果它是一个单点,如果它挂了,那么相应的节点无法执行相应的操作
Zookeeper的设计猜想:
防止单点故障
集群方案(leader、follower)、还能分担请求
每个节点的数据是一致的(必须要有leader)
Leader、master; redis-cluster
Leader挂了怎么办?数据如何恢复
选举机制?数据如何恢复
符合去保证数据一致性?(分布式事务)
一开始单体架构中,CAP一致性是有一个事务去统一控制和管理的,现在一个请求,分到了不同的服务器,但是我还需要保证整个集群,和整个集群是一致的。
每个节点只能保证内部的一致性,我们要保证整体的一致性,zookeeper就引入了改进版的2PC协议去完成2阶提交
2PC 二阶段提交协议
Two Phase Commitment Protocol
当一个事务涉及到多个节点去提交的时候,为了保证事务处理的ACI的特性的话,在2PC中引入了一个概念叫协调者,通过一个协调者来控制各个节点事务的执行逻辑。
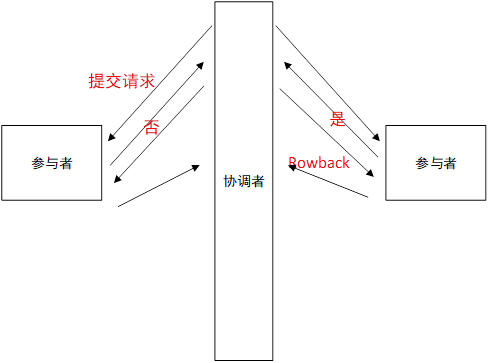
如果参与者1与参与者2中的数据需要都执行成功,才算一次执行成功,
在单体架构中直接通过transactional去直接控制事务的一致性。
在分布式系统中引入一个协调者,协调者先对每一个参与这个事务的参与者提交一次请求,每个参与者收到请求后,会给一个回应,是不是能够执行这个事务,给个是,表示可以执行这次事务,如果每一个参与者都回应一个是,那么就表示这个请求是可以被执行成功的。 这时候协调者就对每一个参与者进行一次commit,然后提交完成以后给一个ack的二阶提交的响应。
假如某一个参与者第一次回应了个否,就意味着整体要全部失败,事务要保证原子性,要么全部成功,要么全部失败。那么对所有的节点发起的是一个rollback操作。这就是一个所谓的二阶段提交的概念。
而zookeeper里边是基于二阶提交的方式去做数据同步的
结论:
为什么用ZAB实现选举(基于proposal思想的,zookeeper里边的协议,解决数据一致性的问题)为什么要做集群为什么通过2PC做数据一致性
Zookeeper的集群
我们现在有一个客户端,对zookeeper集群做出了一个处理
Zookeeper对外有一个集群,客户端进行连接这个集群时,会随机连接某一个节点,
如果当前的请求是读请求,我们的请求可以落在任意一个节点去读取数据。
如果是写请求,那么这个请求会转发给leader去处理
我们说过了,zookeeper是基于一个2PC的方式进行的一个事务的提交
如果我们的一个写请求到了一个follower节点上,它会转发到leader节点上,然后leader节点会发起一个提议,会把事务发给集群中的每一个节点,这时候的follower节点要给leader节点一个ack,这个ack表示当前的这个节点是不是能够执行这个事务,leader一旦发现过半的请求是同意的,我会提交这个事务,然后就返回response。
这就是改进版的2PC的一个事务。然后提交事务以后,数据会同步给observer
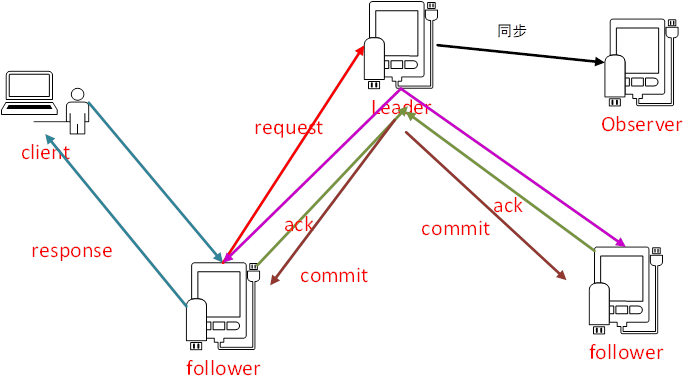
Leader是整个zookeeper集群的核心,起到了主导zookeeper集群的一个作用,比如说我们一个事务请求的一个调度和处理,保证我们集群中事务处理的一个顺序性,
Follower角色主要是用来处理客户端的非事务请求,以及转发事务请求给leader服务器,参与整个事务的投票过程,叫proposal,我们这条数据要保存到zookeeper集群里边,必须要有过半的节点同意,
Observer是一个观察者的角色,相当于我能够了解集群中相关节点的相关变化并且对状态进行同步, observer不参与事务请求的投票,
如果我们想要集群的性能更高,我们肯定想要引入更多的节点,节点越来越多,性能提升了,投票的时候会变慢,不影响整体写性能的情况下,引入observer,提升整体的性能。
所有节点的数量必须是2N+1,我们必须保证有2N+1个节点,叫基础节点,zookeeper集群的工作机制,是必须有半数以上节点能够正常的工作,并且能够参与到投票机制,如果投票不能过半的话,我们的投票是没有结果的。
ZAB协议
(基于Proposal协议衍生出来的一种算法)
ZAB协议是zookeeper里边专门设计的针对崩溃恢复的原子广播协议,
主要用来实现数据一致性
Zookeeper是一种类似于主备的形式,leader挂了,follower上能够选举出一个leader来,接替上一个leader上的服务,通过ZAB协议保证各个节点上数据的一致性,为了保证主备数据的一致性,就需要实现ZAB协议。
崩溃恢复
原子广播
当我们第一次启动集群的时候或者leader集群崩溃的时候,这时候ZAB协议就会产生作用,ZAB协议会进入恢复模式,它会从宕掉的集群里边重新去选举一个leader,并且当新的leader选举出来以后,当集群中过半的机器和新选举的leader完成了数据同步以后,整个集群就进入了一个正常运行的状态,就进入了一个原子广播的阶段。
消息广播:(事务提交)
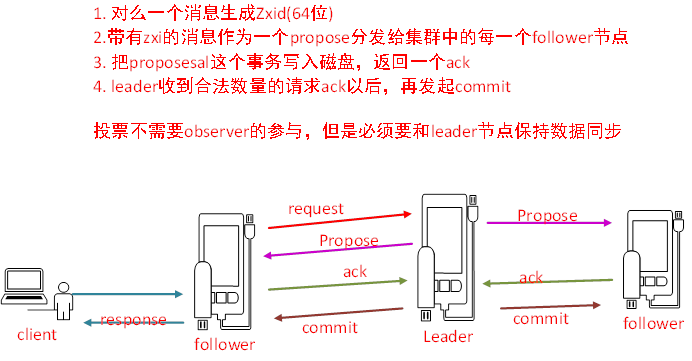
改进版本的2PC
首先当leader收到一个事务请求的时候会生成一个zxid(64位的自增ID)
它会对每一个请求分配一个zxid,
通过zxid的大小可以实现数据的因果有序
Leader对每一个follower都会准备一个IFIO队列,这个是通过TCP协议来实现的,
它会把带有zxid的消息作为一个proposal(提案),分发到集群中的每一个follower节点每一个follower节点收到请求以后,它会把propose这个事务写入到磁盘,返回ack给leaderLeader收到合法数量的请求ack,过半的请求数,同意以后,再发起commit请求
整个一个事务的过程,一个消息广播的过程,
Leader的投票过程和事务的投票过程中不需要observer,但是observer必须保证他的数据和leader的数据是保持一致的
崩溃恢复(对数据层来说)
当leader失去了过半的follower节点的联系
当leader服务挂了
整个集群就会进入崩溃恢复阶段,因为我们必须保证leader挂了之后整个集群还可用。
对于数据恢复来说:
已经被处理的消息不能丢失
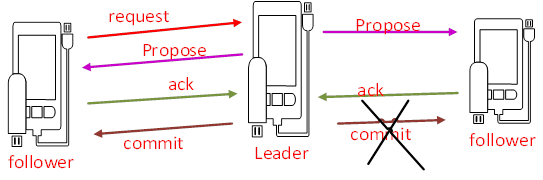
当leader收到合法数量的follower的ack以后,就会向各个follower广播消息(commit命令),同时本地自己也会commit这条事务消息。如果follower节点收到commit命令之前。Leader挂了,会导致部分节点收到commit,部分节点没有收到commit。ZAB协议需要保证已经处理的消息不能丢失。
被丢弃的消息不能再次出现
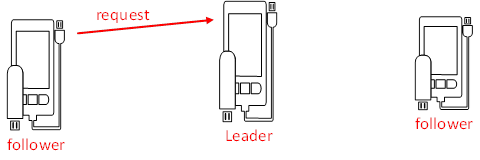
当leader请求收到事务请求,并且还未发起事务投票之前,leader挂了。
下一个leaser,要跳过这个请求。
我们的leader挂掉以后,我们不仅需要重新选举leader,还要恢复我们的数据,
ZAB的设计思想
zxid是最大的? 保证已经提交的proposal一定会被提交!!不会出现数据丢失。epoch的概念,每产生一个新的leader,那么新的leader的epoch会+1
zxid是64位的数据,
低32位表示消息计数器(自增的),高32位(epoch编号)
如果我们新的选举出来的leader,就意味着它的epoch比老的epoch高,它的每一个事务id 都会带上epoch编号,和消息计数器。这样设计以后,当我们重新选举leader以后,消息会重新从0开始,而epoch是老的加上一,好处是:老的服务器重新启动以后,它不会再成为leader,就是在这一轮里边不会在成为leader,并且老的leader,变成follower,加入到集群以后,它的zxid一定会小于新的zxid,那么新的leader,会把他所有没有提交的事务都会清除。
epoch可以理解为年号,皇帝的年号。
实操:
[root@Darian1 bin]# ls /tmp/zookeeper/
myid version-2 zookeeper_server.pid
[root@Darian1 bin]# ls /tmp/zookeeper/version-2/
acceptedEpoch currentEpoch log.1 log.100000001 log.200000001
[root@Darian1 bin]# vim /tmp/zookeeper/version-2/currentEpoch
2
~[root@Darian1 bin]# ls /tmp/zookeeper/
myid version-2 zookeeper_server.pid
[root@Darian1 bin]# ls /tmp/zookeeper/version-2/
acceptedEpoch currentEpoch log.1 log.100000001 log.200000001
[root@Darian1 bin]# vim /tmp/zookeeper/version-2/currentEpoch
2
~# ls /tmp/zookeeper/
# ls /tmp/zookeeper/version-2/# ls /tmp/zookeeper/
# ls /tmp/zookeeper/version-2/
acceptedEpoch cuttentEpoch log.1 log.1000000001 log.3 log.a00000001
# vim /tmp/zookeeper/version-2/currentEpoch
可以看到epoch
:q!
Epoch
我们去关闭leader,
# sh zkServer.sh stop
重新看到epoch
可以看到加了一
Epoch加一,可以保证把以前没有提交的proposal丢弃掉,
# ls /tmp/zookeeper/version-2
查看日志内容
[root@Darian1 bin]# java -cp :/zookeeper/zookeeper-3.4.10/lib/slf4j-api-1.6.1.jar:/zookeeper/zookeeper-3.4.10/zookeeper-3.4.10.jar org.apache.zookeeper.server.LogFormatter /tmp/zookeeper/version-2/log.1
路径:java –cp :/slf4j.jar:/zookeeper.jar org.apache.zookeeper.server.LogFormatter /tmp/zookeeper/version-2/log.1
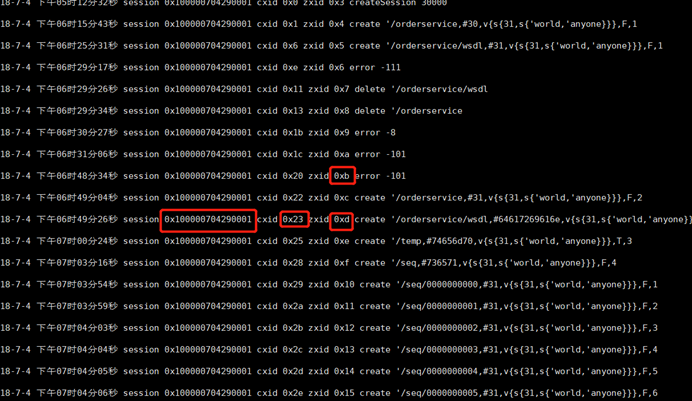
server.1=192.168.136.128:2888:3888
server.2=192.168.136.129:2888:3888
server.3=192.168.136.130:2888:3888
理解ZAB协议
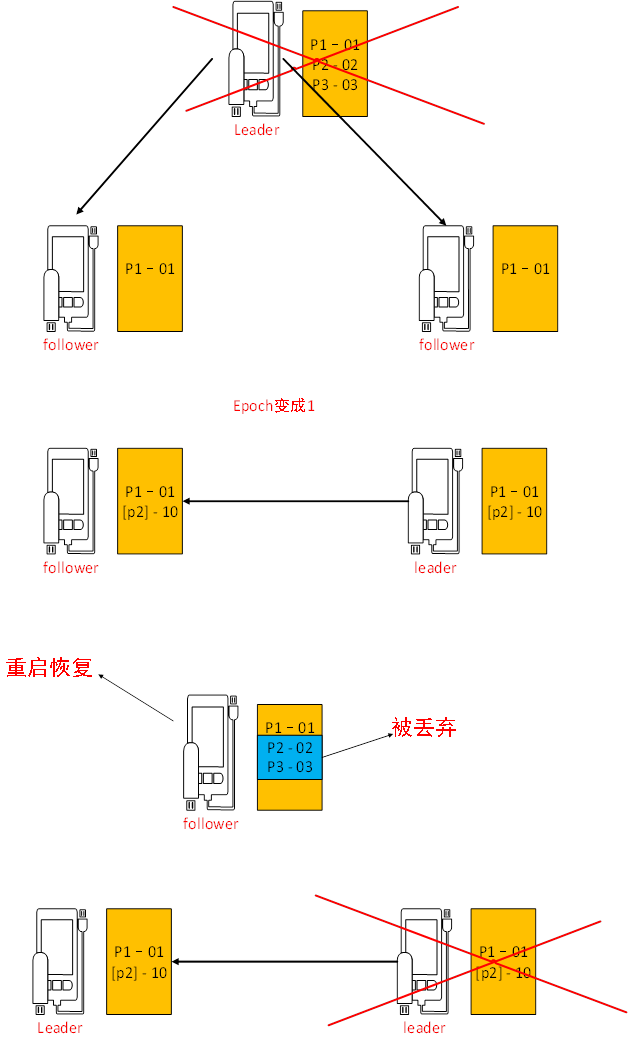
假设leader中有三个事务请求
P1 01
P2 02
P3 03
zxid
它会把这个事务分发给每一个节点去做提交
假设
Follower1 收到了 p1 01
Follower2 收到了 p1 01
其它请求还没有发起,
这时候leader挂了,
这时候我们假设follower1变成了leader
这时候新的leader发起了一个新的事务请求,
[p2] -10
(代表epoch 0 代表消息数)
这个请求同步到follower上 叫 [p2] -10
数据恢复:
确定整个集群里边所有的参与者follower节点要确定事务日志里边的proporess已经被过半的节点提交过了。
Leader会为每一个follower节点准别一个FIFO的队列,把各个follower节点没有被提交的请求,以事务的方式逐步发给其他节点,但是,如果事务是失效的,过期的,它会被丢弃掉。
Leader选举
两种情况会做leader选举,
一个是集群启动,一个是崩溃恢复
Fast Leader 基于fast leader做选举的
Zxid最大会设置为leader【事务id,事务id越大,那么表示数据越新】
64位, 000000000000000001(epoch) 0000000000000000000010
Myid(服务器id,sid)【myid越大,在leader选举机制中权重越大】
epoch【逻辑时钟】【每一轮投票,epoch都会递增】
选举状态(LOOKING)
LEADING
FOLLOWING
OBSERVING
理论
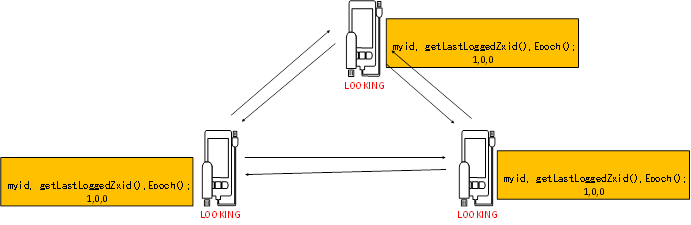
启动的时候初始化,每一个节点会选举自己作为一个leader,把当前节点的这些信息发布给集群中的每一个节点。
(myid, zxid, epoch)
每一个节点会收到这些信息,然后去做投票,
投票过程中会比较对应的数据。
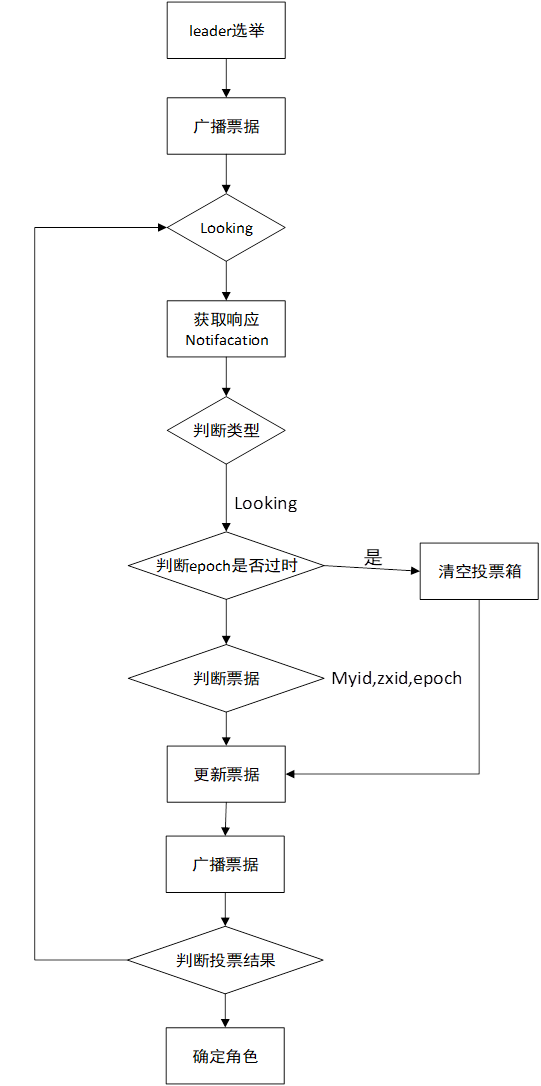
\1. 检查zxid zxid大的节点直接为leader
\2. myid myid比较大的回座位leader
\3. 投票完了以后, 会去统计票数,根据投票结果,确定leader选举的结果。
(4) 统计投票。每次投票后,服务器都会统计投票信息,判断是否已经有过半机器接受到相同的投票信息,此时便认为已经选出了Leader
如果运行过程中的选举的话,leader挂掉了,它可以重新去选举leader,第一个它会去变更状态,把剩下的所有节点都变成一个LOOKING状态去重新做一个监控,监控其他的节点去重新的做一个选举。 接下来跟初始化的都一样了………
zookeeper 的代码入口搜索 QuorumPeerMain
FastLeaderElection 类中 的 lookForLeader方法投票的实现机制
投票流程
判断epochZxid再判断myid
高性能和高可用的集群
热备的集群