
从架构的发展过程说起
什么是zookeeper
Zookeeper安装部署
Zoo.cfg配置文件分析
zookeeper 下边有 zookeeper.out 日志记录
架构不是一蹴而就的,是随着我们业务量的不断增加,不断去演变的。
架构的演变
单体架构 tomcat war

很快的解决产品的迭代问题,交付问题
单体架构
体量增长,后端的架构的性能有瓶颈,后端的架构无法支撑如此大的流量。
垂直的方式,增加硬件设备,增加硬件设备的性能,提升整体的性能。
投入的产出比会越来越小。
然后采用水平的伸缩方式提升架构的性能。
在不改变应用程序和应用程序状态的情况下,通过水平的伸缩去提升整体的性能。
水平伸缩,
对完整的产品进行一个拆分,拆分成不同的模块。
一般来说,对于一个产品一般是根据业务领域进行拆分,
例子:用户服务, 订单服务 商品服务

远程过程调用
例如 :基于SOAP协议的webservice进行远程过程调用,
形成分布式架构
通过不同的计算机网络组成的通过远程过程调用组成的一个整体。
当服务越来越多,通过拆分服务,服务会拆分越来越细,做水平扩展,做集群高可用,
服务成百上千个,某个服务可能做成百上千的集群。
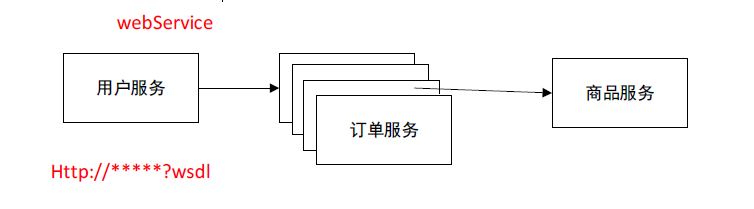
http soap?wsdl
在每个节点上需要去维护远程服务的接口的地址,调用目标服务接口的形式和入参是什么样子的。
调用其他服务是需要根据wsdl文档生成对应的一些代码去做远程过程调用。
拆分服务
如果某一个服务不是一个单一的节点,他进行了成百上千的高可用的配置大规模的集群,
那么就必须得维护成百上千的访问地址的维护。
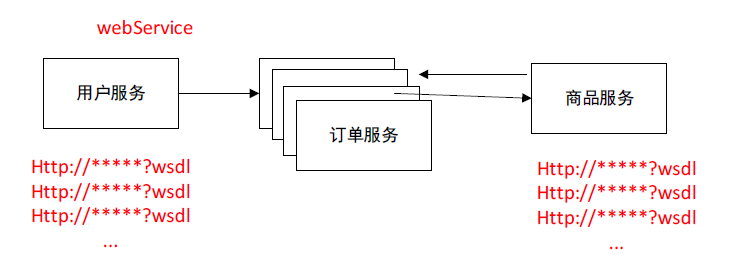
怎么解决地址维护的管理
如何转发,负载均衡
而且调用这个服务时请求如何进行转发。负载均衡机制。
如果集群中的某个节点宕机了怎么办,会有很多错误的请求
产生了三个问题:
协议地址的维护负载均衡机制服务动态的上下线感知
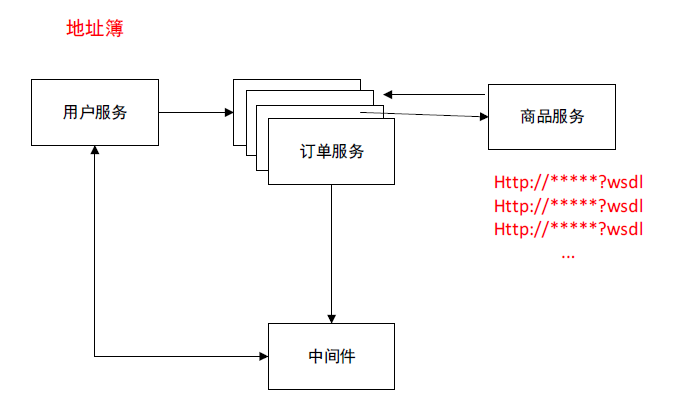
Zookeeper由此产生了。
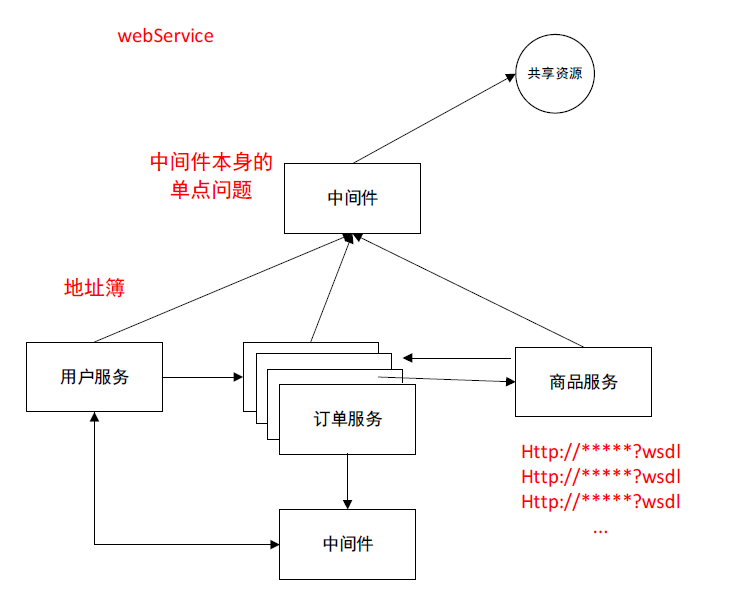
需要有一个中间件,
当服务发布的时候,告诉中间件,(类似于电话簿的功能)这个服务的地址。
他需要记住所有服务的地址,
还需要知道服务断开的话,知道服务断开了
消费端如果需要调用服务端的时候直接去中间件去获得地址。在客户端我不需要一个一个的去维护服务端的地址。在客户端,我只需要维护中间件的地址就好了。从中间件中获得目标服务的信息。拿到目标服务的地址以后就可以做一个转发,List地址簿,根据对应的负载算法,完成一个转发。而且中间件也可以感知服务发布以后的宕机与上线情况。并且客户端,从中间件上拿到地址以后还可以感知到服务端的宕机与上线的变化。
这是我们的目标。
Zookeeper
Zookeeper是一种树形结构
Zookeeper数据的数据方式是基于key-value形式,
但它的存储方式是基于树形的文件方式的存储
所以他每一种服务建立一个结点,在这个节点下在建立多个节点维护地址信息。客户端只需要检测这个结点就可以拿到所有的地址信息,然后进行处理和调用。
有人说zookeeper不适合做注册中心
但是很多公司都用它在做注册中心,问题不是很大。
Zookeeper是一个分布式协调服务
它是一个“动物园”,管理我们中间件的。
Zookeeper历史:
Zookeeper起源于雅虎,一开始是为了解决分布式锁的问题。
如果多个服务调用同一块资源,然后就会存在资源竞争的问题。
多线程是一个进程里边的多个线程的并发的问题。可以通过(synochronized lock)去做
而在分布式架构中是多进程,传统的锁是没办法解决的。
所以我们通过zookeeper去协调在各个节点之间去控制节点的接入顺序,所以叫zookeeper协调。
这是zookeeper最初的设计目标。
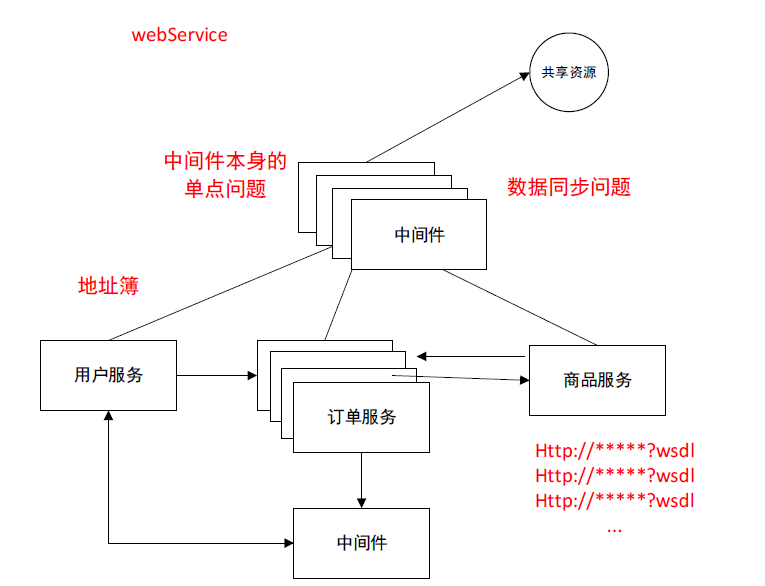
如果在协调的时候成百上千个服务访问同一块资源,这时候就会存在中间件的单点问题。所以我们会对zookeeper做集群。
我们对中间件做集群是为了保证中间件的高性能,高可用。
然后就会存在中间件集群上的数据同步问题。
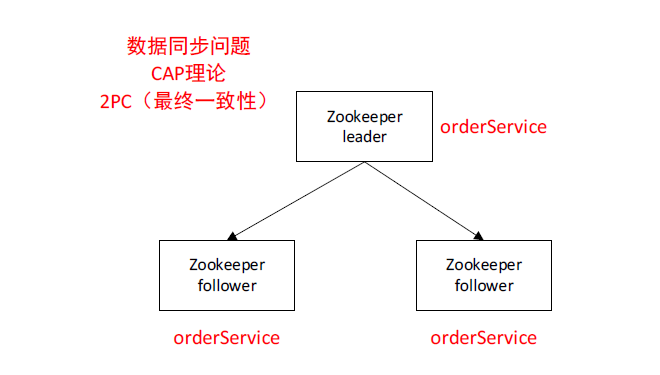
我们zookeeper集群中有一个leader两个slave,我们的每个节点上都要存储数据,
我们
就是我们每一个zookeeper节点上的数据的同步的问题。
CAP理论,既要保证高性能,还要保证高可用是做不到的!!!存在网络通讯的状态。
Zookeeper集群的数据的提交方式是基于2PC的二阶提交的方式去做的。
它的一致性是通过最终一致性来实现的。
Zookeeper可以有多个同级节点。
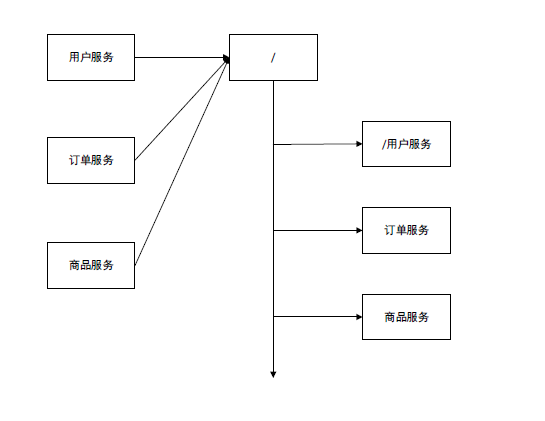
Zookeeper有了很多个服务节点,一个zookeeper上的资源(相当于单点),不同的服务不可以同时的访问这个zookeeper上的资源,这时候就会存在瓶颈,
Zookeeper集群就产生了。
Zookeeper集群是一主多从的机制,
一个leader
Follower follower
做这个集群能够保证流量可以被分摊,同时也可以保证高可用,如果leader坏了,可以进行新的选举,选举出一个新的leader替换上。这是它完成高可用的本身的一种机制。
我们现在的zookeeper是一个集群,我们的客户端可以访问集群中的任意一个节点。
这时候就需要数据的同步。
如果我们用户服务在leader上创建了一个服务,然后订单服务在follower上去查询的时候发现这个服务不存在!! 这时候就存在数据不一致的情况。 因此我们集群就需要涉及到数据的同步。
我们一定要有leader
我们所有的事务请求要放在leader上,我们的其他请求要放在follower上。
如果我们的事务请求可以放在任意一个节点上,这时候就意味着没有中心化节点。
Redis-cluster就是一个无中心化的集群(基于GossIP的协议)
无中心化的时候,那么事务的控制就会变得更加的复杂,
为了简化复杂性,
所以我们一般采取
Leader
Follower follower
集群的机制。
所有的事务请求都落在leader节点上,然后其他请求落在follower节点上
我们的事务请求落在leader上时,需要同步数据到follower上,
这时候数据的同步就涉及了CAP,
这时候既要满足我们可以对外提供服务,也要保证这是高性能的。
如果我们的用户服务往leader上创建了一个节点,但是同步完成之前,我不能给用户一个响应的话,那么这时候用户服务去操作数据的时候就会一直等待。等待的话,它的性能就会降低。所以我们不可能用强一致性。
Zookeeper基于2PC协议完成了一个改造版的2PC协议去保证最终一致性。
去中心化
现在我们的项目都是有一个中心化,有一个项目组长,一帮码农去开发,然后他给你分配任务。
这个时候这个项目组长就是一个中心节点。
如果项目组长身体不好,就会重新选出一个组长来开发,
所谓的去中心化,就是一个团队里边,没有所谓的组长,所有人都是一个平等的,全都是程序猿。然后按照领域去划分任务,一个任务过来了,判断属于哪一个领域,然后谁去处理就好了。去中心化的好处就不会出现单点故障。
全球互联网化就是一个去中心化的思想。就是一个机房中的一个电脑出现故障不会影响整个互联网内其他电脑的是否可以上网,这就是一个去中心化的好处。
通信异常
通过分布式架构演变以后,我们的每一个服务调用,它是基于一个远程服务调用,远程服务通信它本身就是不可靠的,由于一些不可控的因素导致,这个服务在某个时间内是不可用的。如果服务的通信不可用的话,就会存在访问的消息的丢失
存在三态
正常情况下只会存在两种状态
一种是成功,
一种是失败。
然后在分布式机构中会存在第三种状态,
未知状态,可能是超时
可能我们的请求发过去以后,可能已经收到了,处理了,可能一直没有返回,也有可能在返回过程中出现网络故障,就会出现超时。
Zookeeper
Zookeeper 它是一个分布式协调服务,它是由雅虎创建的,是google chubby开源实现的,它是为了解决分布式架构里的复杂的容易出错的一致性的问题,就是我们的协调问题。这是zookeeper设计的初衷。
凡是一些中间件都会有一个配置文件
Zookeeper是开源的,直接在官网上去下载,然后会有一个 tar.gz 的压缩包
# tar –zxvf zookeeper-3.4.10.tar.gz
解压缩以后就可以运行了
解压缩以后可以在zookeeper的目录下
# cd zookeeper-3.4.10
# ls
启动之前还需要改一下配置文件
# cd conf/
Ls
# cp zoo_sample.cfg zoo.cfg
默认会读取zoo.cfg这样一个文件,我们拷贝这样一个文件。
Zookeeper有个一配置文件,凡是中间件都有一个对完的配置文件,去对一些参数做一些优化和去配置一些可自定义的一些参数
# vim zoo.cfg
可以看到一些配置文件
# cd ..
# cd bin/
进入到bin目录下
# sh zkServer.sh start
然后zookeeper启动以后
# sh zkCli.sh
连接
这样我们就连接到了远程服务,我们通过客户端连接到了远程服务,然后我们可以进行一些操作。
WatchedEvent state:SyncConnected type:None path:null
[zk: localhost:2181(CONNECTED) 0]
[zk: localhost:2181(CONNECTED) 0]
[zk: localhost:2181(CONNECTED) 0]
[zk: localhost:2181(CONNECTED) 0]
[zk: localhost:2181(CONNECTED) 0]
[zk: localhost:2181(CONNECTED) 0]
[zk: localhost:2181(CONNECTED) 0]
[zk: localhost:2181(CONNECTED) 0]WatchedEvent state:SyncConnected type:None path:null
[zk: localhost:2181(CONNECTED) 0]
[zk: localhost:2181(CONNECTED) 0]
[zk: localhost:2181(CONNECTED) 0]
[zk: localhost:2181(CONNECTED) 0]
[zk: localhost:2181(CONNECTED) 0]
[zk: localhost:2181(CONNECTED) 0]
[zk: localhost:2181(CONNECTED) 0]
[zk: localhost:2181(CONNECTED) 0]我们一个客户端通过zkClient.sh去访问zookeeper,然后就可以远程操作命令,
Zookeeper是一个树形的操作结构,它只是一个树形结构,但是数据都会存在节点上
Help
ZooKeeper -server host:port cmd args
stat path [watch]
set path data [version]
ls path [watch]
delquota [-n|-b] path
ls2 path [watch]
setAcl path acl
setquota -n|-b val path
history
redo cmdno
printwatches on|off
delete path [version]
sync path
listquota path
rmr path
get path [watch]
create [-s] [-e] path data acl
addauth scheme auth
quit
getAcl path
close
connect host:portZooKeeper -server host:port cmd args
stat path [watch]
set path data [version]
ls path [watch]
delquota [-n|-b] path
ls2 path [watch]
setAcl path acl
setquota -n|-b val path
history
redo cmdno
printwatches on|off
delete path [version]
sync path
listquota path
rmr path
get path [watch]
create [-s] [-e] path data acl
addauth scheme auth
quit
getAcl path
close
connect host:port数据怎么去创建,涉及到创建命令
客户端要发起一些命令去操作这些节点
增 create
删 delete
改 set
查 get
创建的时候必须一层一层创建。
删除的时候必须一层一层的往上删除。
Help
命令可以看到
Create /orderservice 0
Ls /
Create path value
作为一个设计者,一定要具备节点的唯一性,在当前的节点下,不能出现名字一样的两个节点
Zookeeper的特性:
同级节点的唯一性临时节点和持久化节点的特性有序节点和无序节点节点存在父子关系,必须有先后临时节点下不能存在子节点
临时节点的特性:
在客户端简历的会化周期中,创建的临时节点,会话结束以后会自动删除。
有序节点:
我们如果创建的是有序节点的话,会带一个数字 00000000000001
00000000000002
创建一个节点
[zk: localhost:2181(CONNECTED) 31] create /orderservice 1
Created /orderservice
[zk: localhost:2181(CONNECTED) 32] create /orderservice/wsdl darian
Created /orderservice/wsdl
[zk: localhost:2181(CONNECTED) 33] get /orderservice/wsdl
darian
cZxid = 0xd
ctime = Wed Jul 04 18:49:26 CST 2018
mZxid = 0xd
mtime = Wed Jul 04 18:49:26 CST 2018
pZxid = 0xd
cversion = 0
dataVersion = 0
aclVersion = 0
ephemeralOwner = 0x0
dataLength = 6
numChildren = 0[zk: localhost:2181(CONNECTED) 31] create /orderservice 1
Created /orderservice
[zk: localhost:2181(CONNECTED) 32] create /orderservice/wsdl darian
Created /orderservice/wsdl
[zk: localhost:2181(CONNECTED) 33] get /orderservice/wsdl
darian
cZxid = 0xd
ctime = Wed Jul 04 18:49:26 CST 2018
mZxid = 0xd
mtime = Wed Jul 04 18:49:26 CST 2018
pZxid = 0xd
cversion = 0
dataVersion = 0
aclVersion = 0
ephemeralOwner = 0x0
dataLength = 6
numChildren = 0Create –s –e path data acl
-s sequence 有序
-e ephemeral 临时特性
我们可以基于这两个参数去创建我们的节点。
Create –s /seq 1
自动的都会有一个序号
有序节点
[zk: localhost:2181(CONNECTED) 40] create -s /seq/ 1
Created /seq/0000000000
[zk: localhost:2181(CONNECTED) 41] create -s /seq/ 1
Created /seq/0000000001
[zk: localhost:2181(CONNECTED) 42] create -s /seq/ 1
Created /seq/0000000002
[zk: localhost:2181(CONNECTED) 43] create -s /seq/ 1
Created /seq/0000000003
[zk: localhost:2181(CONNECTED) 44] create -s /seq/ 1
Created /seq/0000000004
[zk: localhost:2181(CONNECTED) 45] create -s /seq/ 1
Created /seq/0000000005
[zk: localhost:2181(CONNECTED) 46][zk: localhost:2181(CONNECTED) 40] create -s /seq/ 1
Created /seq/0000000000
[zk: localhost:2181(CONNECTED) 41] create -s /seq/ 1
Created /seq/0000000001
[zk: localhost:2181(CONNECTED) 42] create -s /seq/ 1
Created /seq/0000000002
[zk: localhost:2181(CONNECTED) 43] create -s /seq/ 1
Created /seq/0000000003
[zk: localhost:2181(CONNECTED) 44] create -s /seq/ 1
Created /seq/0000000004
[zk: localhost:2181(CONNECTED) 45] create -s /seq/ 1
Created /seq/0000000005
[zk: localhost:2181(CONNECTED) 46]查看节点
[zk: localhost:2181(CONNECTED) 46] ls /seq
[0000000001, 0000000000, 0000000003, 0000000002, 0000000005, 0000000004][zk: localhost:2181(CONNECTED) 46] ls /seq
[0000000001, 0000000000, 0000000003, 0000000002, 0000000005, 0000000004]Ctrl + c 断开连接
再次连接上,临时节点就被删除了
Key-value形式可以存储序列化的对象。
节点必须有父节点,才能创建子节点。
Zoo_sample.cfg里边
dataDir=tmp/zookeeper :存储数据的文件的路径
zookeeper默认读取 zoo.cfg 文件
zkCli.sh zookeeper自带的客户端脚本
临时节点下不能有子节点
[zk: localhost:2181(CONNECTED) 2] create -e /tmp 1
Created /tmp
[zk: localhost:2181(CONNECTED) 3] create /tmp/aaa 3
Ephemerals cannot have children: /tmp/aaa
[zk: localhost:2181(CONNECTED) 4] create -e /tmp/aaa 3
Ephemerals cannot have children: /tmp/aaa
[zk: localhost:2181(CONNECTED) 5][zk: localhost:2181(CONNECTED) 2] create -e /tmp 1
Created /tmp
[zk: localhost:2181(CONNECTED) 3] create /tmp/aaa 3
Ephemerals cannot have children: /tmp/aaa
[zk: localhost:2181(CONNECTED) 4] create -e /tmp/aaa 3
Ephemerals cannot have children: /tmp/aaa
[zk: localhost:2181(CONNECTED) 5]配置zookeeper集群
可能需要安装vim 插件 yum install -y vim
vim zoo.cfg
下边加上
前边是集群之间通信的接口,后边是用来选举的端口
server.id=ip:port:port
server.1=192.168.136.128:2888:3888
server.2=192.168.136.130:2888:3888
server.3=192.168.136.131:2888:3888
(启动一次zookeeper才有对应的目录)
# vim /tmp/zookeeper/myid
在data目录下创建myid(id一定要和上面id对应的ip对应)
i
把server的id放进去
查看进程
# ps –ef|grep zookeeper
Kill -9 40290
直接关掉进程
sh zkServer.sh stop
看一下日志:
tail –f zookeeper.out
2018-07-05 00:52:30,493 [myid:1] - INFO [QuorumPeer[myid=1]/0:0:0:0:0:0:0:0:2181:QuorumPeer$QuorumServer@184] - Resolved hostname: 192.168.168.131 to address: /192.168.168.131
2018-07-05 00:52:30,493 [myid:1] - INFO [QuorumPeer[myid=1]/0:0:0:0:0:0:0:0:2181:FastLeaderElection@847] - Notification time out: 60000
2018-07-05 00:53:30,510 [myid:1] - WARN [QuorumPeer[myid=1]/0:0:0:0:0:0:0:0:2181:QuorumCnxManager@584] - Cannot open channel
to 2 at election address /192.168.136.130:38882018-07-05 00:52:30,493 [myid:1] - INFO [QuorumPeer[myid=1]/0:0:0:0:0:0:0:0:2181:QuorumPeer$QuorumServer@184] - Resolved hostname: 192.168.168.131 to address: /192.168.168.131
2018-07-05 00:52:30,493 [myid:1] - INFO [QuorumPeer[myid=1]/0:0:0:0:0:0:0:0:2181:FastLeaderElection@847] - Notification time out: 60000
2018-07-05 00:53:30,510 [myid:1] - WARN [QuorumPeer[myid=1]/0:0:0:0:0:0:0:0:2181:QuorumCnxManager@584] - Cannot open channel
to 2 at election address /192.168.136.130:3888这个时候会报
Cannot open channel to 3 at election address /192.168.111.155:3888
这个端口是用来做leader选举的
报错
Java.net.NoRouteToHoHostExceptoion:No route to host
防火墙没有关
systemctl stop firewalld
关闭防火墙
成功启动了
2018-07-05 01:05:18,440 [myid:1] - INFO [LearnerHandler-/192.168.136.131:33468:LearnerHandler@346] - Follower sid: 3 : info : org.apache.zookeeper.server.quorum.QuorumPeer$QuorumServer@30dac10b
2018-07-05 01:05:18,448 [myid:1] - INFO [LearnerHandler-/192.168.136.131:33468:LearnerHandler@401] - Synchronizing with Follower sid: 3 maxCommittedLog=0x1b minCommittedLog=0x1 peerLastZxid=0x0
2018-07-05 01:05:18,448 [myid:1] - WARN [LearnerHandler-/192.168.136.131:33468:LearnerHandler@468] - Unhandled proposal scenario
2018-07-05 01:05:18,448 [myid:1] - INFO [LearnerHandler-/192.168.136.131:33468:LearnerHandler@475] - Sending SNAP
2018-07-05 01:05:18,449 [myid:1] - INFO [LearnerHandler-/192.168.136.131:33468:LearnerHandler@499] - Sending snapshot last zxid of peer is 0x0 zxid of leader is 0x100000000sent zxid of db as 0x1b
2018-07-05 01:05:18,457 [myid:1] - INFO [LearnerHandler-/192.168.136.131:33468:LearnerHandler@535] - Received NEWLEADER-ACK message from 3
2018-07-05 01:05:18,457 [myid:1] - INFO [QuorumPeer[myid=1]/0:0:0:0:0:0:0:0:2181:Leader@962] - Have quorum of supporters, sids: [ 1,3 ]; starting up and setting last processed zxid: 0x100000000
2018-07-05 01:05:22,252 [myid:1] - INFO [LearnerHandler-/192.168.136.130:50564:LearnerHandler@346] - Follower sid: 2 : info : org.apache.zookeeper.server.quorum.QuorumPeer$QuorumServer@7d15c17f
2018-07-05 01:05:22,261 [myid:1] - INFO [LearnerHandler-/192.168.136.130:50564:LearnerHandler@401] - Synchronizing with Follower sid: 2 maxCommittedLog=0x1b minCommittedLog=0x1 peerLastZxid=0x0
2018-07-05 01:05:22,261 [myid:1] - WARN [LearnerHandler-/192.168.136.130:50564:LearnerHandler@468] - Unhandled proposal scenario
2018-07-05 01:05:22,261 [myid:1] - INFO [LearnerHandler-/192.168.136.130:50564:LearnerHandler@475] - Sending SNAP
2018-07-05 01:05:22,262 [myid:1] - INFO [LearnerHandler-
/192.168.136.130:50564:LearnerHandler@499] - Sending snapshot last zxid of peer is 0x0 zxid of leader is 0x100000000sent zxid of db as 0x100000000
2018-07-05 01:05:22,270 [myid:1] - INFO [LearnerHandler-/192.168.136.130:50564:LearnerHandler@535] - Received NEWLEADER-ACK message from 22018-07-05 01:05:18,440 [myid:1] - INFO [LearnerHandler-/192.168.136.131:33468:LearnerHandler@346] - Follower sid: 3 : info : org.apache.zookeeper.server.quorum.QuorumPeer$QuorumServer@30dac10b
2018-07-05 01:05:18,448 [myid:1] - INFO [LearnerHandler-/192.168.136.131:33468:LearnerHandler@401] - Synchronizing with Follower sid: 3 maxCommittedLog=0x1b minCommittedLog=0x1 peerLastZxid=0x0
2018-07-05 01:05:18,448 [myid:1] - WARN [LearnerHandler-/192.168.136.131:33468:LearnerHandler@468] - Unhandled proposal scenario
2018-07-05 01:05:18,448 [myid:1] - INFO [LearnerHandler-/192.168.136.131:33468:LearnerHandler@475] - Sending SNAP
2018-07-05 01:05:18,449 [myid:1] - INFO [LearnerHandler-/192.168.136.131:33468:LearnerHandler@499] - Sending snapshot last zxid of peer is 0x0 zxid of leader is 0x100000000sent zxid of db as 0x1b
2018-07-05 01:05:18,457 [myid:1] - INFO [LearnerHandler-/192.168.136.131:33468:LearnerHandler@535] - Received NEWLEADER-ACK message from 3
2018-07-05 01:05:18,457 [myid:1] - INFO [QuorumPeer[myid=1]/0:0:0:0:0:0:0:0:2181:Leader@962] - Have quorum of supporters, sids: [ 1,3 ]; starting up and setting last processed zxid: 0x100000000
2018-07-05 01:05:22,252 [myid:1] - INFO [LearnerHandler-/192.168.136.130:50564:LearnerHandler@346] - Follower sid: 2 : info : org.apache.zookeeper.server.quorum.QuorumPeer$QuorumServer@7d15c17f
2018-07-05 01:05:22,261 [myid:1] - INFO [LearnerHandler-/192.168.136.130:50564:LearnerHandler@401] - Synchronizing with Follower sid: 2 maxCommittedLog=0x1b minCommittedLog=0x1 peerLastZxid=0x0
2018-07-05 01:05:22,261 [myid:1] - WARN [LearnerHandler-/192.168.136.130:50564:LearnerHandler@468] - Unhandled proposal scenario
2018-07-05 01:05:22,261 [myid:1] - INFO [LearnerHandler-/192.168.136.130:50564:LearnerHandler@475] - Sending SNAP
2018-07-05 01:05:22,262 [myid:1] - INFO [LearnerHandler-
/192.168.136.130:50564:LearnerHandler@499] - Sending snapshot last zxid of peer is 0x0 zxid of leader is 0x100000000sent zxid of db as 0x100000000
2018-07-05 01:05:22,270 [myid:1] - INFO [LearnerHandler-/192.168.136.130:50564:LearnerHandler@535] - Received NEWLEADER-ACK message from 2查看节点的状态:
sh zkServer.sh status
[root@Darian1 bin]# sh zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /zookeeper/zookeeper-3.4.12/bin/../conf/zoo.cfg
Mode: leader[root@Darian1 bin]# sh zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /zookeeper/zookeeper-3.4.12/bin/../conf/zoo.cfg
Mode: leaderZookeeper JMX enabled by default
Using config: /data/program/zookeeper-…….
Mode: follower
到follower中可以看到数据的同步现象
sh zkCli.sh
ls /
在 data 目录下创建myid(id一点给要和上面的id对应的ip对应)
Observer
在集群中还有一个Observer的角色
Observer
起到一个监控的作用
在不影响整个集群性能的情况下,还能够知道整个集群的状态
回顾:
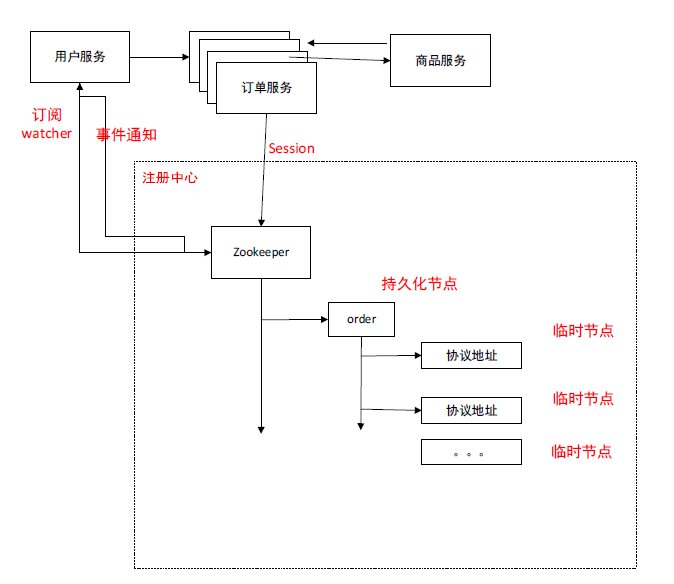
我们希望有一个中间件可以实现我们的服务发现,地址感知,和负载均衡。
所以有了zookeeper
我们需要一个注册中心去注册我们的地址,我们的客户端都去调用zookeeper上的地址,
被调用方在zookeeper上创建节点
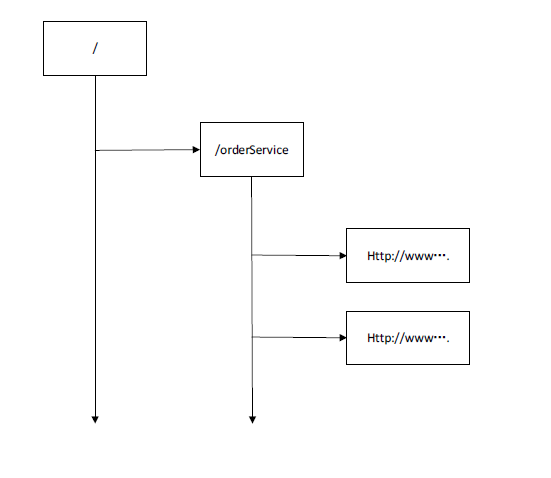
订单服务在zookeeper上创建了一个order节点,(持久化节点)
然后我们在order节点下可以创建很多个节点,每个节点上存的是对应的协议地址,可以创建多个。如果此刻这个服务的集群有一千个,那么我需要在这个节点下维护一千个地址。
我们的协议地址,就需要用临时节点。
我们前边说要做到服务动态上下线感知。就意味着,我这个服务宕机以后这个节点要有体现。这个节点会自动删除。
临时节点的好处:它的生命周期和当前的会话是保持一致的。
我们启动以后,通过我们的封装,就是底层的封装,dubbo就是这样封装的,
调用方,连接zookeeper拿到这个信息,
叫做订阅:
订阅:叫做watcher机制
就是对应节点如果发生变化了,会有一个事件通知。
节点下一旦发生地址的变化。就会有通知。我们就可以拿到相应的数据去做处理。去判断当前节点的状态,或者我们去更新当前节点的信息。就能够拿到我们最新的地址,以及我们拿到地址以后就可以做负载均衡。
先了解zookeeper的核心:
cd conf/
任何中间件里边都有一个配置文件,redis有一个叫redis.cfg
Zookeeper有一个叫zoo.cfg
Nginx有一个配置文件叫nginx.cfg
因为中间件需要提供一些需要优化的配置,我们可以去调整我们的线程,调整我们的缓冲区,去配置我们的相关地址。
详细配置去官网上看,可以根据需要去做很多的调整
TickTime-2000
它可以理解成一个时间单位,是我们zookeeper里边最小的时间单位是毫秒
是2毫秒 相当于我们定义 了一个时间单位的规则。
initLImit=10
初始化,就是初始化同步数据的时候 ,10表示10个tickTime
最大的同步时间,初始化时间。
syncLimit=5
发起一个请求,和获得请求的状态的一个时间,就是数据同步的时间
这是leader和follower之间的心跳检测最大延迟,是5个tickTime ,就是10秒钟。
如果集群中我们的follower节点不可用,或者我们的leader节点不可用,这时候这样的一个心跳检测就会出现一个故障,如果心跳出现一个故障,就意味着整个集群中出现某个节点不可用,就会重新去选举
dataDir=/tmp/zookeeper
这是大家关注的。
我们对应的事务的日志文件会存在dataDir文件里边,
[root@Darian1 conf]# ls /tmp/zookeeper/version-2/
acceptedEpoch currentEpoch log.1 log.100000001 log.200000001[root@Darian1 conf]# ls /tmp/zookeeper/version-2/
acceptedEpoch currentEpoch log.1 log.100000001 log.200000001Tmp是一个临时节点,所以我们不建议放在这个目录下,我们建议独立挂载在一个SSD的高速磁盘上,因为磁盘的读取速度决定了我们zookeeper集群的一个性能,因为我们的每一个事务请求,就是我们的每一个insert,update 和 delete,是属于事务请求,那么每一个事务请求,它都会先去记录事务日志,所以记录日志这个盘写入比较慢,那么这个整体的性能就会受到很大的影响。
clientPort=2181
客户端和服务端连接的时候用到的一个端口
跟redis:6379 tomcat 8080
这是一个对外提供的一个开放的端口
Server.1=192.168.11.153:2888:3888
后边对应的是myid myid是默认找到dataDir里边的一个myid文件,去读取这个id,
这个id后边会用
这个myid对应的ip地址,通信端口号,选举端口
ls /tmp/zookeeper/version-2
可以看到
AcceptedEpoch
currentEpoh
log.1
log.3
策略
打开我们的zookeeper客户端
sh zkCli.sh
Ls /
可以看到节点
我们用到了很多命令,去做了一些简单的策略,比说临时节点策略和持久节点策略
(m 修改 modifier 修改)
get /zzz
去获取一个几点的话可以获得很多信息
[zk: localhost:2181(CONNECTED) 4] get /seq
seq
cZxid = 0xf
ctime = Wed Jul 04 19:03:16 CST 2018
mZxid = 0xf
mtime = Wed Jul 04 19:03:16 CST 2018
pZxid = 0x15
cversion = 6
dataVersion = 0
aclVersion = 0
ephemeralOwner = 0x0
dataLength = 3
numChildren = 6[zk: localhost:2181(CONNECTED) 4] get /seq
seq
cZxid = 0xf
ctime = Wed Jul 04 19:03:16 CST 2018
mZxid = 0xf
mtime = Wed Jul 04 19:03:16 CST 2018
pZxid = 0x15
cversion = 6
dataVersion = 0
aclVersion = 0
ephemeralOwner = 0x0
dataLength = 3
numChildren = 6value值
cZxiid= 0x1000000000003
表示事务id,我们去创建一个节点的时候相当于发起一个事务请求,他会有个事务id
ctime=Sun Jun 03 21:08:21 CST 2019
创建时间
mZxid=0x100000000000003
我们对节点进行更改的时候,进行更新事务,就会有更新事务id,如果我们之创建了节点以后他的创建id和更新id是一样的。
mtime= Sun Jun 03 21:08:21 CST 2019
修改时间
pZxid=0x1000000000003
这个表示当前节点下,最后一次被修改的时候,他的一个事务id,会放到pZxid里边。
只有子节点变更以后才会产生pZxid的影响
cversion=0
当前节点的子节点版本号
dataVersion=0
当前数据内容它的版本号
aclVersion=0
当前权限变更的版本号
这时候有一个version,它是一个乐观锁的概念,我们会通过一个版本号去维护数据的版本,如果说我们a,b同时去修改一个数据,这个数据修改以后它的版本发生了变化,a先,b后的话,b基于以前的数据进行修改的话,得到的数据不对,这就是我们乐观锁的概念。通过版本号去维护数据的状态。
这些版本号用来控制数据的并发性,因为zookeeper一定存在并发访问。记录版本号,防止对脏数据的一个修改,导致最终数据不一致,所以我们在修改的时候可以传一个版本号。
(我们在更新节点的时候传入一个版本号 set /zzz value 0 ,这时候dataaVersion=1,
我们在set /zzz value 0,这个时候它会报错,version No is not valid : /mic 这就是我们用版本号去控制被错误修改的一个重要的手段)
[zk: localhost:2181(CONNECTED) 7] set /seq aa 0
cZxid = 0xf
ctime = Wed Jul 04 19:03:16 CST 2018
mZxid = 0x200000003
mtime = Thu Jul 05 15:54:53 CST 2018
pZxid = 0x15
cversion = 6
dataVersion = 1
aclVersion = 0
ephemeralOwner = 0x0
dataLength = 2
numChildren = 6
[zk: localhost:2181(CONNECTED) 8] set /seq aa 0
version No is not valid : /seq
[zk: localhost:2181(CONNECTED) 9] set /seq bb 1
cZxid = 0xf
ctime = Wed Jul 04 19:03:16 CST 2018
mZxid = 0x200000005
mtime = Thu Jul 05 15:56:21 CST 2018
pZxid = 0x15
cversion = 6
dataVersion = 2
aclVersion = 0
ephemeralOwner = 0x0
dataLength = 2
numChildren = 6
[zk: localhost:2181(CONNECTED) 10][zk: localhost:2181(CONNECTED) 7] set /seq aa 0
cZxid = 0xf
ctime = Wed Jul 04 19:03:16 CST 2018
mZxid = 0x200000003
mtime = Thu Jul 05 15:54:53 CST 2018
pZxid = 0x15
cversion = 6
dataVersion = 1
aclVersion = 0
ephemeralOwner = 0x0
dataLength = 2
numChildren = 6
[zk: localhost:2181(CONNECTED) 8] set /seq aa 0
version No is not valid : /seq
[zk: localhost:2181(CONNECTED) 9] set /seq bb 1
cZxid = 0xf
ctime = Wed Jul 04 19:03:16 CST 2018
mZxid = 0x200000005
mtime = Thu Jul 05 15:56:21 CST 2018
pZxid = 0x15
cversion = 6
dataVersion = 2
aclVersion = 0
ephemeralOwner = 0x0
dataLength = 2
numChildren = 6
[zk: localhost:2181(CONNECTED) 10]ephemeralOwner=0X0
创建临时节点以后才会有的, 我们创建一个临时节点之后,get /temp之后
这个客户端与zookeeper会有一个绘画的标志,通过这个标志,我们可以知道这个连接断开以后我们应该把那些临时节点都删掉,这个就是用来绑定当前会话的信息
dataLength=3
当前数据的长度
numChildren=0
当前子节点的一个数量
每一个滴答声的毫秒数
tickTime = 2000
最初的蜱虫数量
同步阶段可以
initLimit = 10
可以在两者之间传递的节拍数
发送请求并获得确认
syncLimit = 5
存储快照的目录。
不要使用/tmp存储,/tmp只是
#例子的缘故。
dataDir = / tmp /动物园管理员
客户端连接的端口
clientPort = 2181
客户端连接的最大数量。
如果你需要处理更多的客户,就增加这个
# maxClientCnxns = 60
#
请务必阅读以下内容的维护部分
管理员指南,在开启自动提醒之前。
#
# http://zookeeper.apache.org/doc/current/zookeeperAdmin.html sc_maintenance
#
在dataDir中保留的快照数量
# autopurge.snapRetainCount = 3
在小时内清除任务间隔
设置为“0”以禁用自动清除功能
# autopurge.purgeInterval = 1每一个滴答声的毫秒数
tickTime = 2000
最初的蜱虫数量
同步阶段可以
initLimit = 10
可以在两者之间传递的节拍数
发送请求并获得确认
syncLimit = 5
存储快照的目录。
不要使用/tmp存储,/tmp只是
#例子的缘故。
dataDir = / tmp /动物园管理员
客户端连接的端口
clientPort = 2181
客户端连接的最大数量。
如果你需要处理更多的客户,就增加这个
# maxClientCnxns = 60
#
请务必阅读以下内容的维护部分
管理员指南,在开启自动提醒之前。
#
# http://zookeeper.apache.org/doc/current/zookeeperAdmin.html sc_maintenance
#
在dataDir中保留的快照数量
# autopurge.snapRetainCount = 3
在小时内清除任务间隔
设置为“0”以禁用自动清除功能
# autopurge.purgeInterval = 1ACL
ACL是一个权限控制
Zookeeper提供了一种类似于linux的一种类似于文件控制权限的一种方式。去控制你创建的文件夹的访问权限。比如说我们创建了某一个节点,只能读,或只能让某一个用户访问怎么办。就是通过ACL去控制
ACL定义了五中权限
CREATE/READ/WRITE/DELETE/ADMIN
每一权限控制的粒度不一样,控制的方向不一样,这就是我们节点的一个特性。
名词复盘:
集群角色
我们集群中有leader follower,各个集群之间是可以通信的。
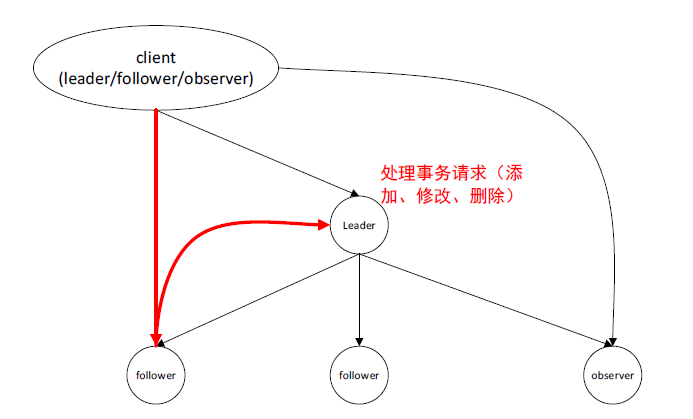
Leader
Follower follower observer
Leader是用来处理事务请求的,所有的添加,修改,删除,可以理解为一个读写分离的概念。
如果我们客户端将事务请求发给了follower,那么这个follower会把请求转发给leader
默认的数据库会打开一个事务的请求。Observer是一个监视,Observer只负责去leader节点同步数据,不会参与这个节点的选举,不涉及到选举,就不会有性能的开销。它的数据的同步就不需要做到一个实时。Observer节点是可以去配置的
数据模型:
Zookeeper核心的东西
我们可以创建多个节点,
每个节点下我们又可以创建多个节点。
节点:
持久化节点
持久化有序节点
临时节点
临时有序节点
统计节点的唯一性
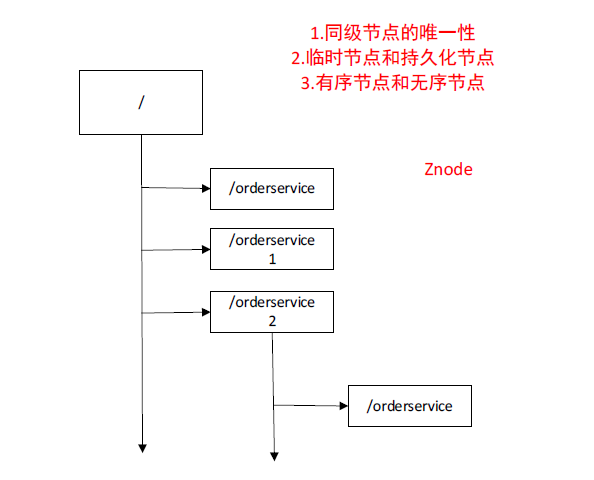
每一个节点叫做znode,表示他的最小的一个数据单位的名称叫做znode。
Znode上可以保存少量的数据,不建议保存太多。因为如果你一个节点的数据量很大,那么同步的性能就会很低,第二个,你如果要获得这样一个节点信息,需要通过网络的传输。那么如果数据包比较大,那它就会比较慢。
会话:
会话是个概念,就是客户端与服务端进行一次连接时,就会产生一次会话。
就像我们创建一个数据库的连接会建立一个connection,创建一个redis的连接,会建立一个redis-connection,这就是一个连接。这样的连接底层就是一个TCP连接
那么连接的状态有几种,它是变化的。

首先是没有连接的状态 NOT CONNECTED 默认状态
然后在发起连接 CONNECTING 客户端去初始化连接的时候
然后客户端连接成功以后 CONNECTED 就是连接成功的一个状态
最后处理完成以后 CLOSE
这是一个会话的声明周期
Connected也有可能变成connecting 客户端丢失连接的时候,然后他就会去重试连接,然后他充实连接的此时是可以在zoo.cfg中去配置的。如果一致连接不上,就会变成close的状态。主动关闭这个连接,会话失效
这是zookeeper里边会话状态的一个改变。
Status
节点的属性,前边有!!!
Watcher机制
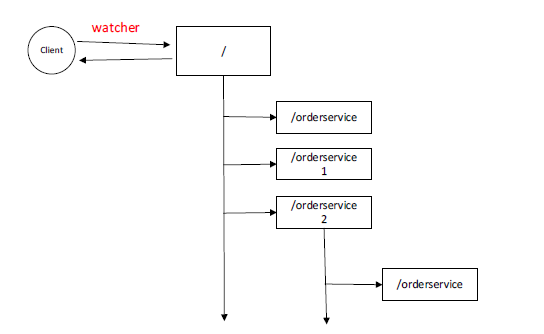
我们客户端可以去监听某一个节点,可以去watcher某一个节点,它watcher了
客户端去watcher这个节点以后,意味着接下来这个节点下的数据的变更,它会有个事件通知,类似于分布式系统的发布订阅,这就是一个事件的通知,我们的客户端就可以被动的知道服务器端的协定信息的状态以及我们节点变更以后更新的一个操作。
ACL权限控制
上边有!!!
Zookeeper的应用场景:
Zookeeper可以实现注册中心,通过注册中心拿到一些对应的信息。这是zookeeper第一个特性。
配置中心
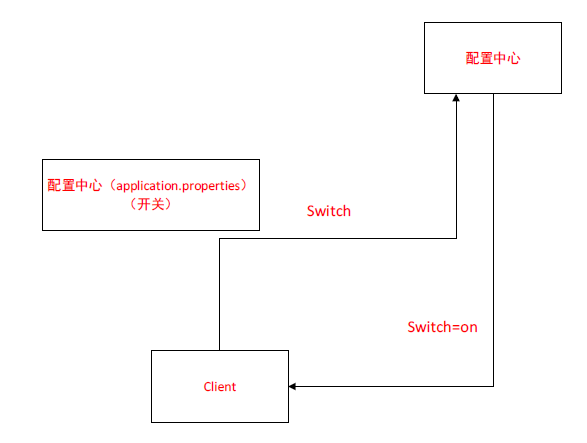
我们还可以实现配置中心。他们实现起来有点大同小异,但在实际使用过程中是不一样的。
我们开发程序时都会存在一个总的配置文件叫:比如说application.context , application.properties 这样一个文件。
这样的文件会维护在每一个对应的项目里边,比如说我们存在一些数据库的配置,一些常量的配置。我们都放在配置文件里边,后续修改起来很麻烦,第二个维护起来工作量大。
第三个在于我们的开关,怎么去做。比如说我们要去控制流程的走向。我们通过一个开关的方式去控制,那如果我们现在要将整个工程变成另外一个方向去走的话。
比如所我们if 走 A if 走B else 走C,
然后我们现在需要流程变化了,我们需要去重新更改配置文件,去发布,读取配置文件,或者也可以去动态监控这个配置文件。实现起来很麻烦。
如果这个开关需要同步给多个节点,我们就需要在每个节点去实现这样的一个功能。所以我们就需要一个配置中心来统一的维护,可以在上边托管的一些配置,客户端要访问要去拿这个配置的话,我要去配置中心去拿到这个值, 你给配置中心一个switch,配置中心告诉你的value是这个switch=on,我拿到这个值就可以去判断,这样子就是一个配置中心的一个概念。
那么zookeeper实现配置中心有两个好处。
第一个,我们可以去监听某个节点的变化,可以去watcher,我就可以不需要主动的去拿,然后动态的去感知,动态的push过来。 这是第一个。
第二个,zookeeper它里边本身的一个节点的特性,就是我们可以通过节点去管理我们相应的一些相关的数据,还有它本身提供了安全机制。
第三个,我们可以去对节点做一个安全方式的处理,
所以这是zookeeper能够实现配置中心的好处,还有zookeeper的性能也很高。
Zookeeper 可以实现负载均衡
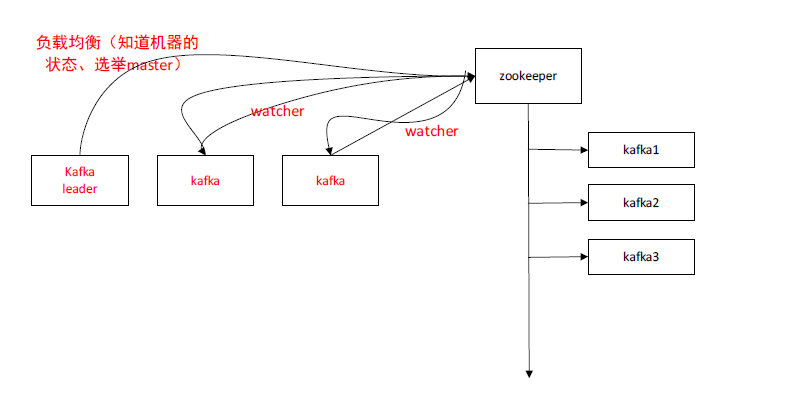
负载均衡有两个点:
第一个我要知道机器的状态选举master
我们选举master和zookeeper的leader的选举有什么区别,
我们可以去基于zookeeper去实现leader选举,比如说kafka是基于zookeeper去实现的,比如说我现在要建立一个kafka集群,有三个节点,怎么实现集群?当然kafka集群不是内部去实现的,zookeeper内部是通过leader选举通过ZAB协议进行选举的,这是它内部提供的机制,但其他的中间件没有。
Kafka是基于zookeeper,在zookeeper上去注册节点
Kafka01 kafka02 kafka03
那我们每一个kafka启动的时候都往zookeeper上去注册一个节点,同一个节点下点的,节点最小就是leader
这样子我们就zookeeper的机制去完成对kafka集群的选举,
如果对应kafka集群的leader节点挂掉了,这时候zookeeper有一个事件,事件可以通知给其它的节点。当前这个leader节点挂掉了。(watcher)。拿到这个通知以后,又要重新的进行选举,然后再拿到最小的节点 kafka2 拿到,把它定义成为master,
这是zookeeper实现负载均衡的概念
是基于zookeeper的提醒去实现其它节点的一个功能与管理
所以说zookeeper是一个分布式协调服务,
所以它能够协调很多服务的特性
Zookeeper还可以实现分布式锁
Watcher机制的演示
连接上zookeeper客户端以后
Get /zzz true
表示这个节点变化以后有一个事件通知,
然后连上另一个客户端,
Set /zzz true
在get的那个客户端中就会看到一个提醒:
WATCHER::
WatchedEvent state:SyncConnected type:NodeDataChanged path:/mic
我们在zookeeper上通过它的节点的特性,是一个文件结构的方式,创建节点会有一个结点的顺序,那我们可以通过客户端去访问节点的时候,去创建节点,最小的节点就是leader,基于zookeeper去实现选举
乐观锁:
每一个数据都存在一个版本号。Get /mic
可以得到一个版本号 当前是一个3
然后另一个设置一下 set /mic 3 版本号为4
但是我们 set /mic bbb 3 这时候我们传递之前的一个版本号,
他会报错 version No is not valid : /mic
数据版本号的变化是通过乐观锁去实现的
Zookeeper的选举有三种方式
创建节点的时候会直接存在磁盘里,有事务日志
前边的端口是用来做数据同步的,
后边的端口是用来做leader选举时用的,
Leader的选举(当服务初步起来的时候,或者leader挂掉的时候就会进行leader的选举)
Observer
Observer在不影响zookeeper得写性能的情况下,zookeeper在leader上执行一个写操作,同步给其他的节点,访问量越来越大以后,我们的整个集群就会很大,我们增加一个节点,会增加一些吞吐量,但是也会带来数据同步的性能上的问题。Zookeeper集群整体写的性能就会下降,所以zookeeper里边节点变更,
数据过来以后,我需要半数的投票以后,才能够告诉客户端已经存储了,这个时候就涉及到数据的同步,observer加到里边,不会参与到投票,所以observer可以提升性能
Observer涉及到选举,不参与投票
我们的key-value 的value一般不存什么内容,就基于节点的特性去实现
日志上不显示哪一台是leader,只能通过状态去显示哪一个是leader
用kafka必须安装zookeeper