
分布式架构的演进过程
- 了解分布式架构中的相关概念
- 初始分布式架构的意义
- 分布式架构的发展过程和历史
- 分布式架构的演进过程
- 构建分布式架构最重要的因素
了解分布式结构中的相关概念
第一个计算机时代
集中式到分布式的发展历史
1946年ENIAC第一台计算机美国,
单台的计算机的性能不断的提升
M级别的内存到现在G级别的内存
图灵,冯诺依曼
图灵:贡献了图灵机的理论模型
冯诺依曼:提出了计算机体系结构的设想
五个部分组成
- 运算器
- 控制器
- 存储器
- 输入设备
- 输出设备
第二个计算机时代(大型主机时代)
IBM主导的大型主机时代
第三个计算机时代
CISC 面向个人的pc
面向个人的pc
RISC 面向企业小型linux的服务器(精简指令集)
注重高性能的主机
现在的编程语言越来越完善。
编程语言发展历程:
机器语言>>>>汇编语言
常用的指令集制定出一套标准
指令集功能化模块化的出现提升了性能。
指令集在计算机性能提升方面有一个非常大的里程碑。
Inter 出名的处理器8086
处理器加入很多指令去提升计算机的性能。
二八理论
20有用,80很少用
80%的指令集只有在20%的场合里去使用
基于晶体管的电脑
如果一个电脑包含所有的指令集,就会出现一种情况:
80%的指令集是不经常用的,20%的指令集会被经常调用
CISC(桌面级)
RISC(精简指令集)
大型计算机是主流,凭借IO处理能力和稳定性、安全性!!!
基于大型主机进行的集中式架构,计算
大型主机的问题
- 复杂性,运维和维护很贵
- 很贵,
- 大型主机是一个单点的机器
- 我们的摩尔定律,个人电脑不断提升
去IOE
09年阿里发起了去IOE运动(利用国内外的开源中间件实现分布式架构)
- IBM的小型机
- ORACLE数据库(商业数据库)
- EMC的存储设备
13年完成最后一台小型机的替换。
12年开源了Dubbo
分布式架构好处:
- 吞吐量很高
- 迭代很快
分布式架构的意义
- 单机的提升投入产出比不高
- 单机处理的瓶颈
- 稳定性和可用性
分布式架构的常见概念
集群
分布式
节点
副本机制
中间件
集群
分布式
我把一个业务按照某种规则去拆分的方式
分成多个模块
多个模块之间进行消息通讯
然后达到一个整体。
应用层的分布式架构。
应用层按照某种领域去拆分 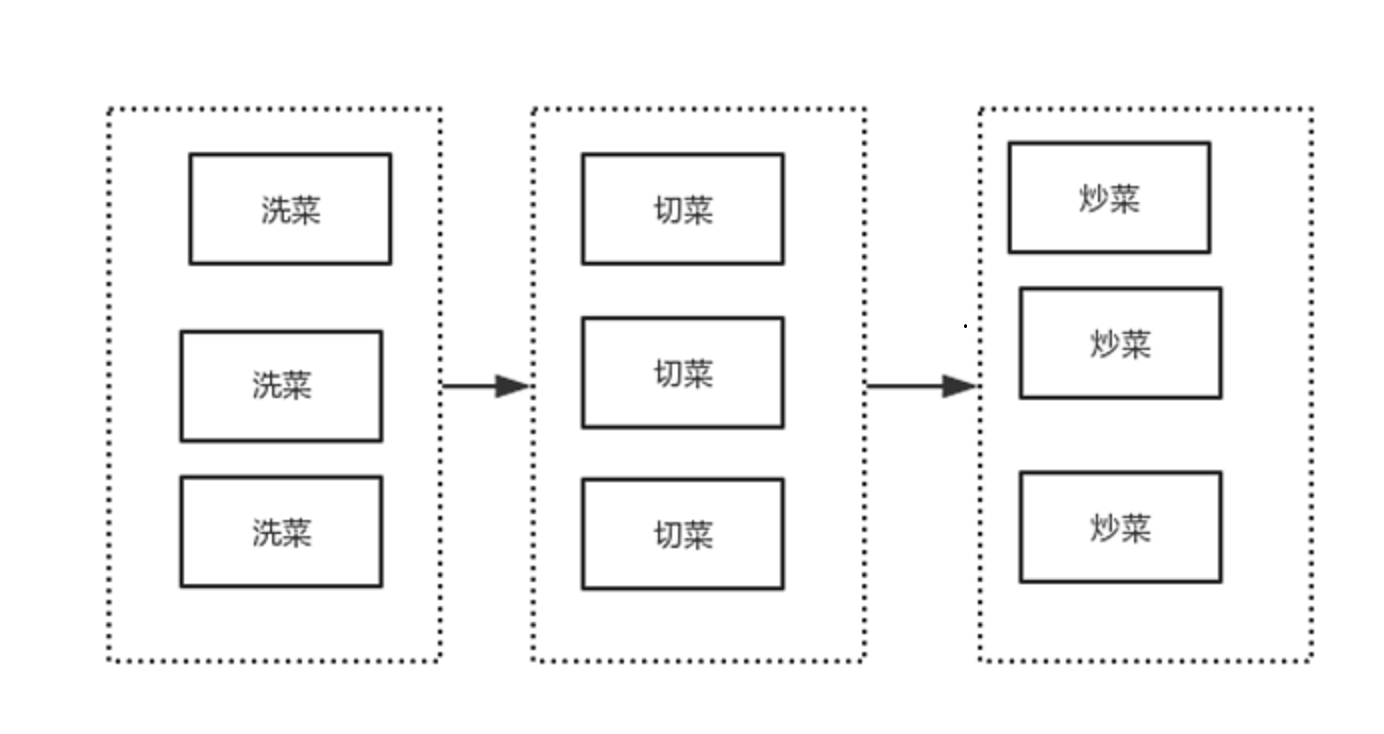
DDD领域驱动
节点
独立按照分布式协议去完成一个完整逻辑的个体。叫做一个节点
数据副本
数据的相互备份:数据副本的概念。避免单点故障
中间件
中间:应用层和操作系统之间的一个位置。
这个软件提供了一个操作系统服务之外的一些服务,而且也不能定义为应用层面的叫中间件。
能够让程序开发人员,更方便的去输入输出,通讯,关注他自己关注的领域
(消息中间件,缓存中间件,RPC框架)
架构发展过程
架构跟着业务去发展,架构支持一定的并发量。
需要前瞻性的考虑一些问题
业务有多大体量,我去支撑就好了
电商平台架构的发展历程。
- 按照产品维度去看待问题
- 给予数据量、访问量的提升
- 网站的结构发生了变化
单一的架构
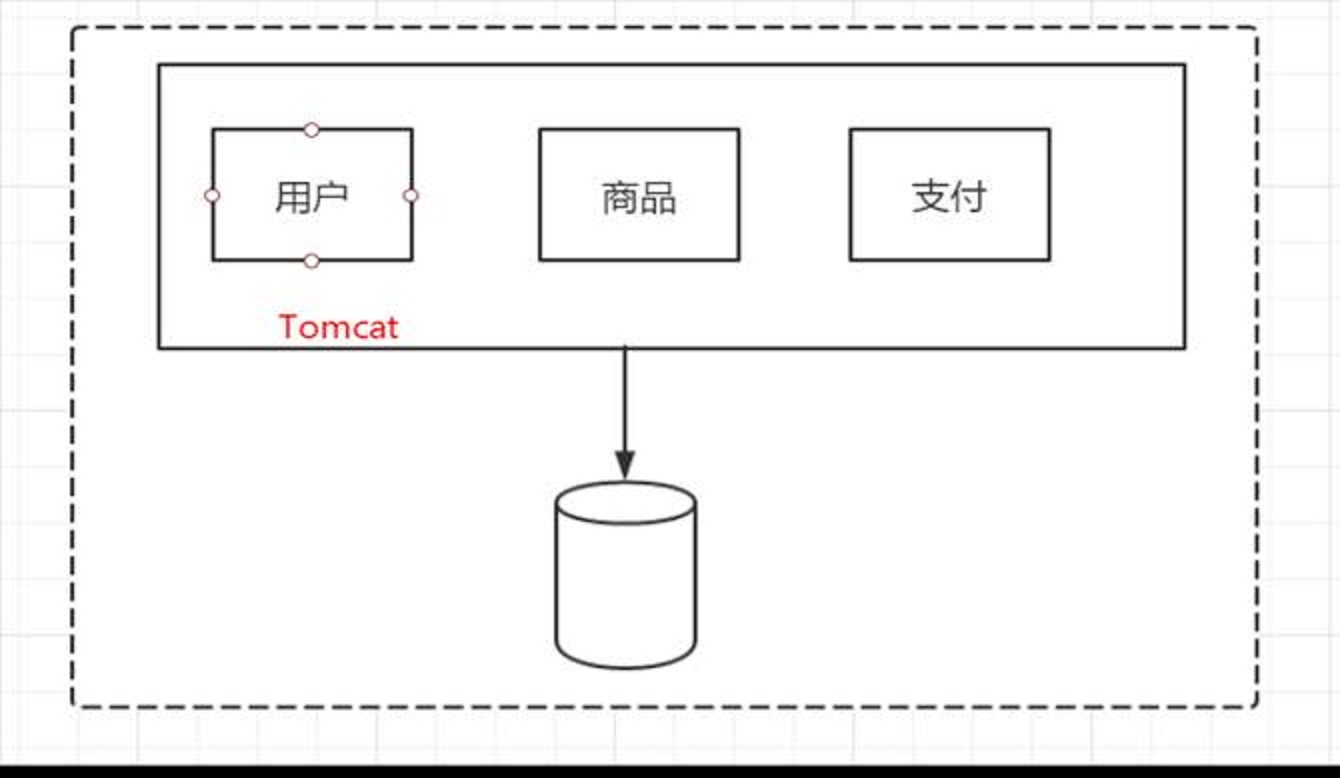
定义一些指标,检测用户的访问量,以及监控后台CPU的使用情况。
被动的服务卡掉了
应用和数据分离
便于针对某个服务器做垂直升级
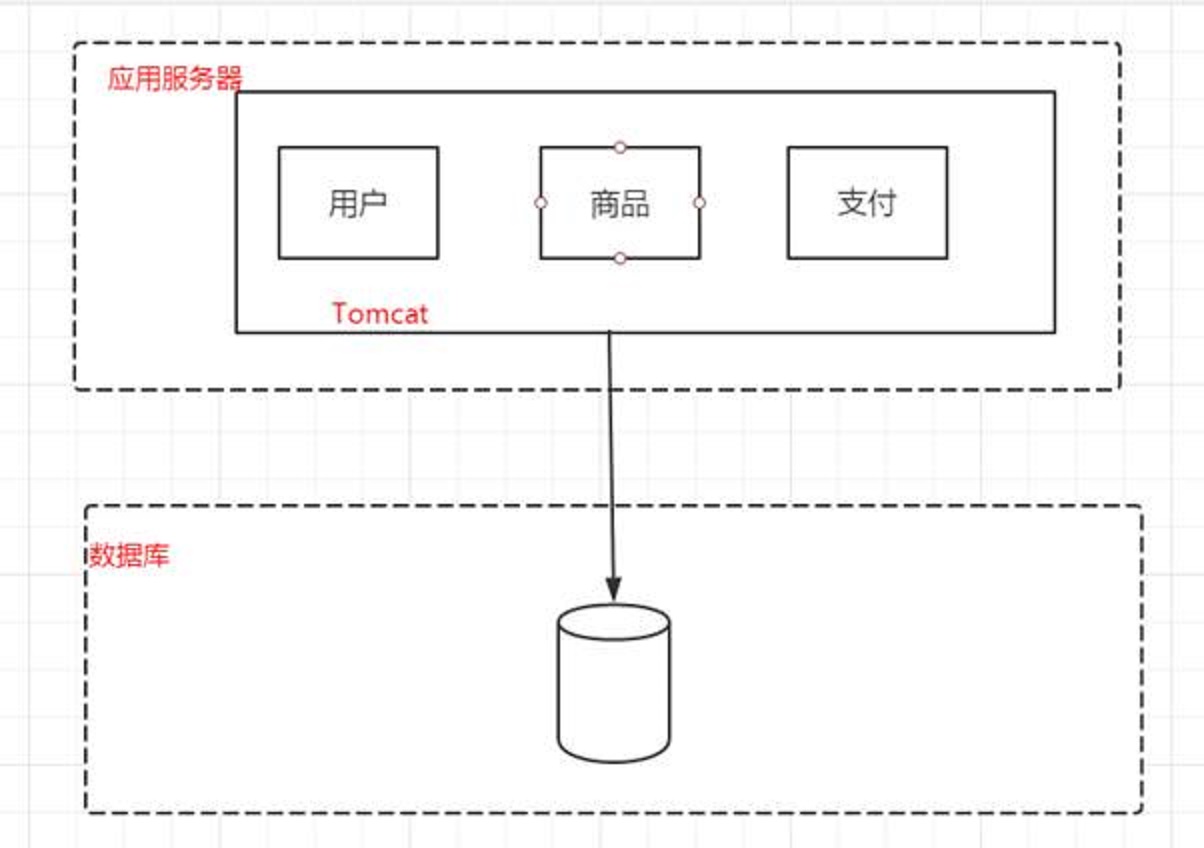
集群架构
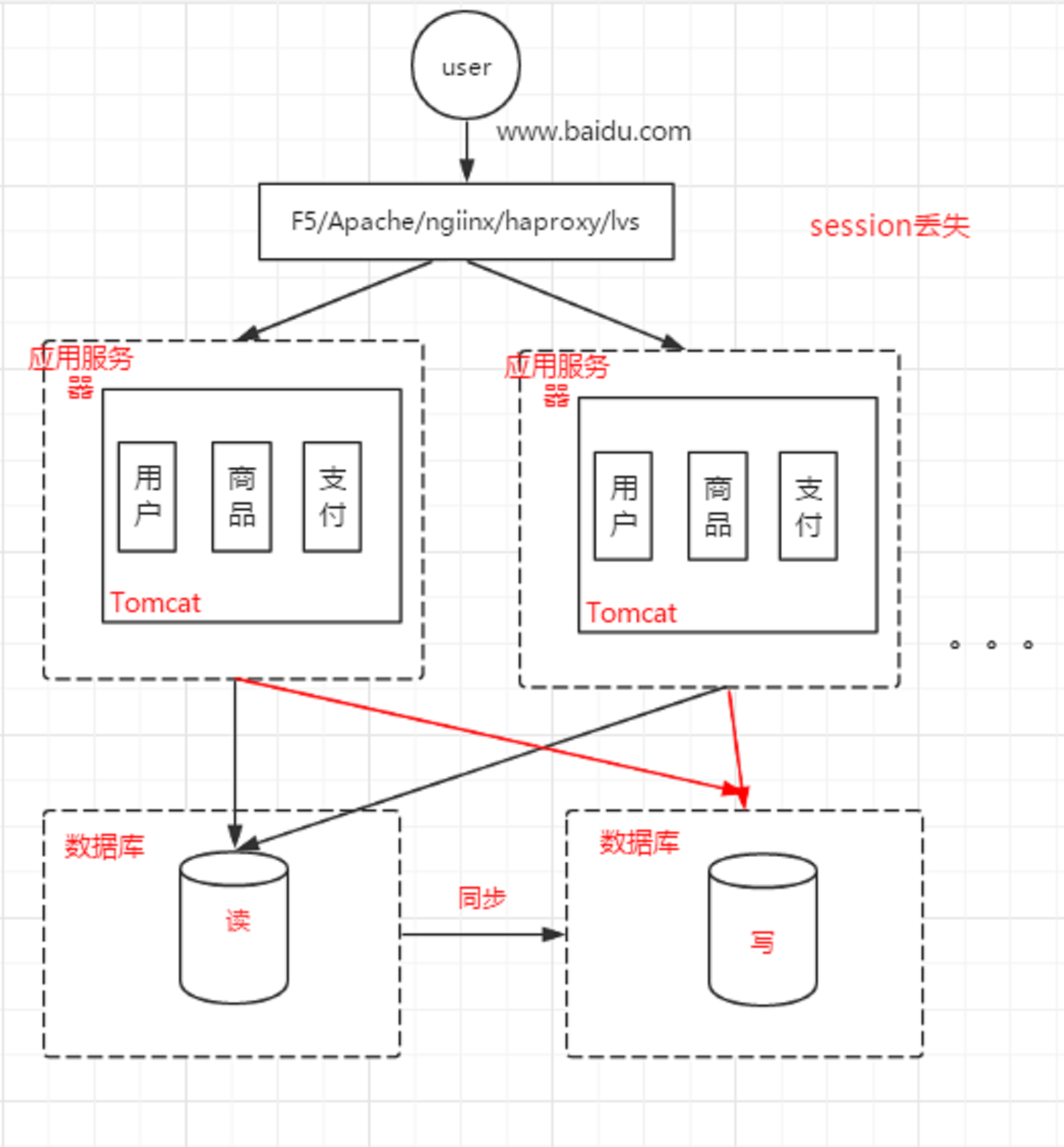
通过域名去访问,
DNS去解析,ip地址+端口号。
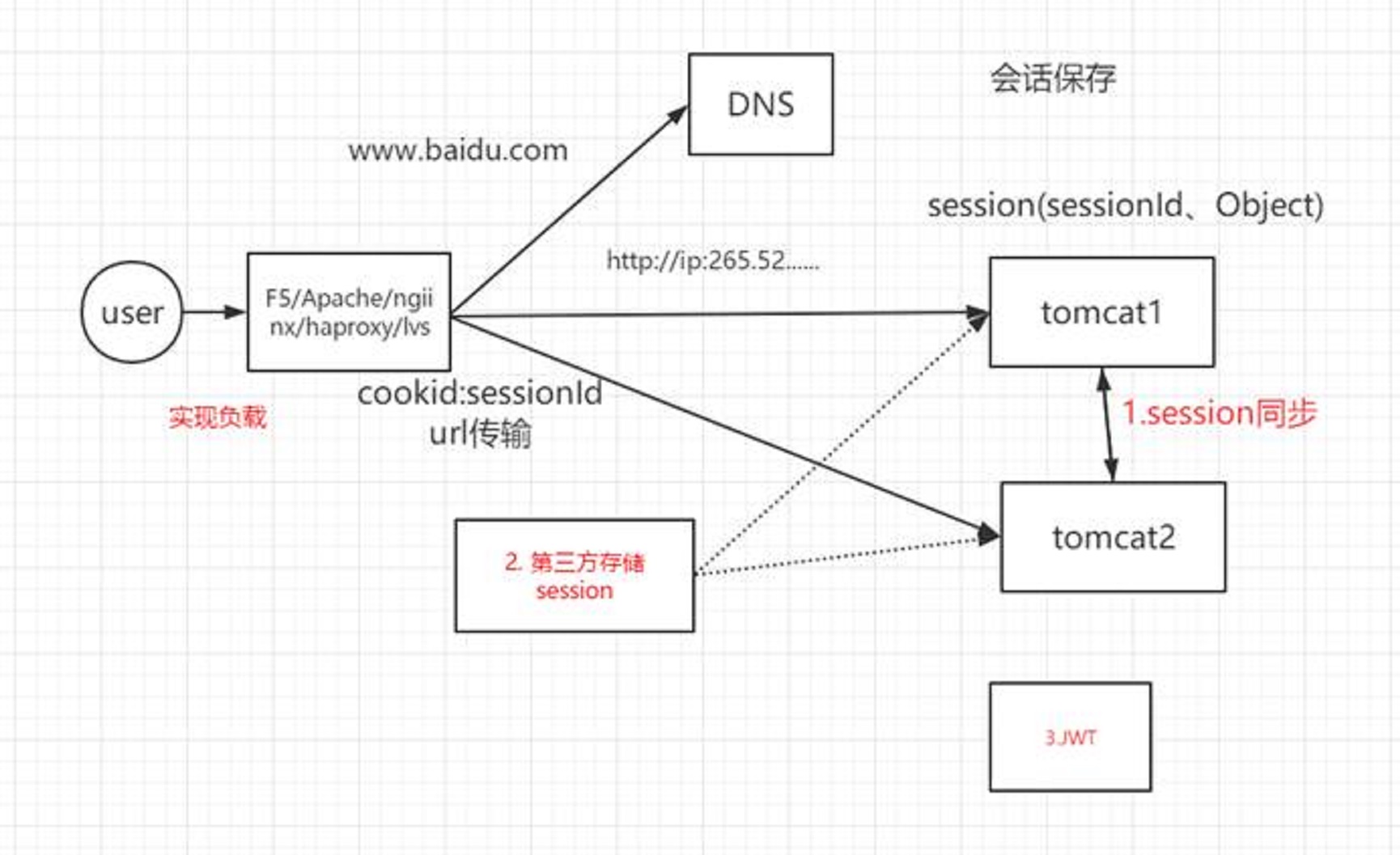
http:无状态。
通过session保存会话状态,tomcat中生成的。
Session是服务端的对象,
Cookie是浏览器的对象。
Cookie中存储sessionId
完成会话状态的保存。
Cookie有有效范围
Session会丢失
集群,访问到不同的服务其上边。
数据库读写分离-优化
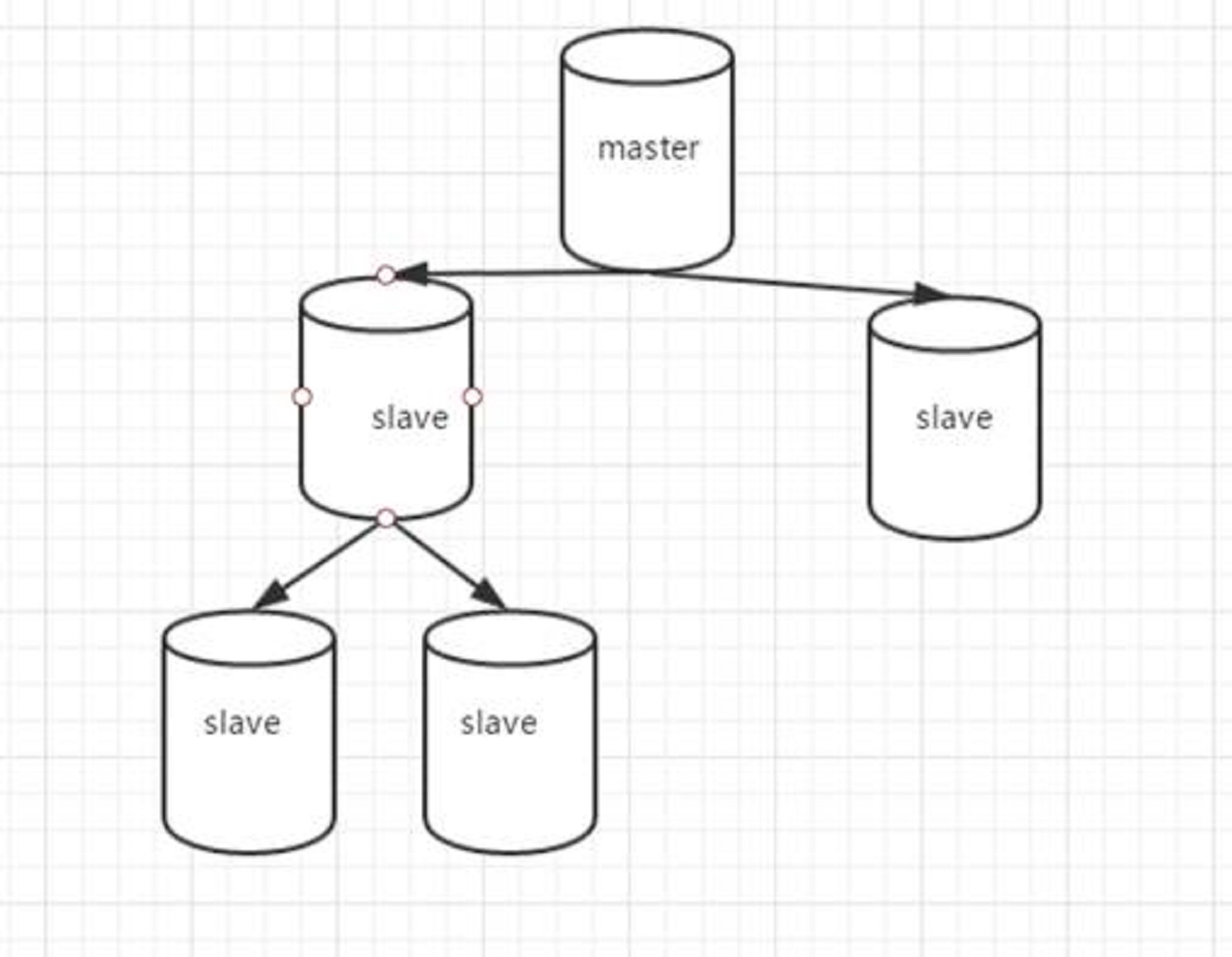
数据库的水平拆分,
读写分离。
通过什么方式做数据的路由。
用什么做mysql的数据同步。
Binglog
网络延迟带来的短暂的不同步的状态
减轻读库的压力。
DB mycat做数据路由的中间件。
搜索引擎做检索的问题
Slor luence electicsearch
ES 基于源数据做一个索引,
全量的同步,还是增量的同步
同步同步,还是异步同步。
数据分析,智能推送
基于访问量激增,
很多人会访问同一块数据,热点数据,
经常访问,频繁访问的。
缓存中间件
用缓存中间件 redis做缓存中间件。
最早的缓存来源来自于CPU的缓存。
应用层面利用缓存,
基于源数据的副本,
NoSql not only sql
非关系型数据库的数据存储。
利用redis做缓存。
- 缓存雪崩
- 缓存击穿
- 缓存的持久化
基于缓存做双读双写,
数据库与缓存之间的同步问题
这中间会有一致性的问题。
先读缓存,再读数据库
怎么解决。
数据库问题
PV 即 Page View,页面浏览量, 用户每一次对网站中的每个页面访问均被记录1次。用户对同一页面的多次刷新,访问量累计。
PV, GV 方面
数据IO
数据量大
IO大的话,性能会降低
数据量大的话,性能会降低,
数据可以垂直分库
按照业务的纬度拆分数据库,不同的业务所使用的数据库放在不同的数据库中。
对数据库进行独立的部署,IO的问题。
分库分表,
分库:垂直拆分
分表:水平拆分(分片)
数据量大的问题。
一亿的数据量,
- 数据库做隔离,
- 保证在线数据,离线数据的指标
- 运维人员与使用人员的隔离。
数据库可以看作是分布式
Redis可以看做是分布式数据库。
开发,运维需要拆分,
架构最终图
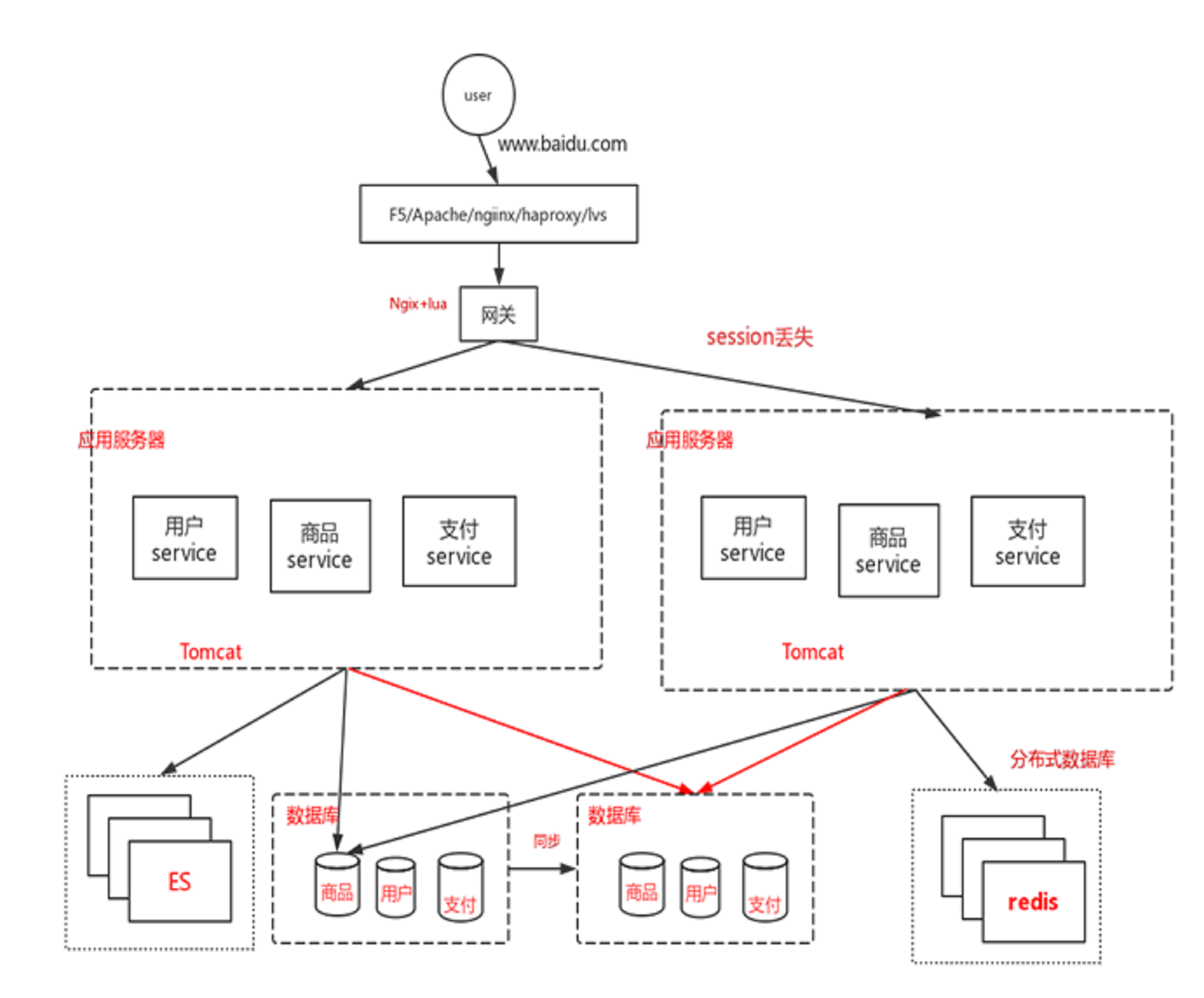
领域驱动
业务模型,按照领域驱动做拆分,
每一个模块做一个单独的项目
可以独立发布,或者做集群。
提炼
一个服务的提炼,对外有web,有service的调用。
模块之间可以相互调用
Rpc、http,
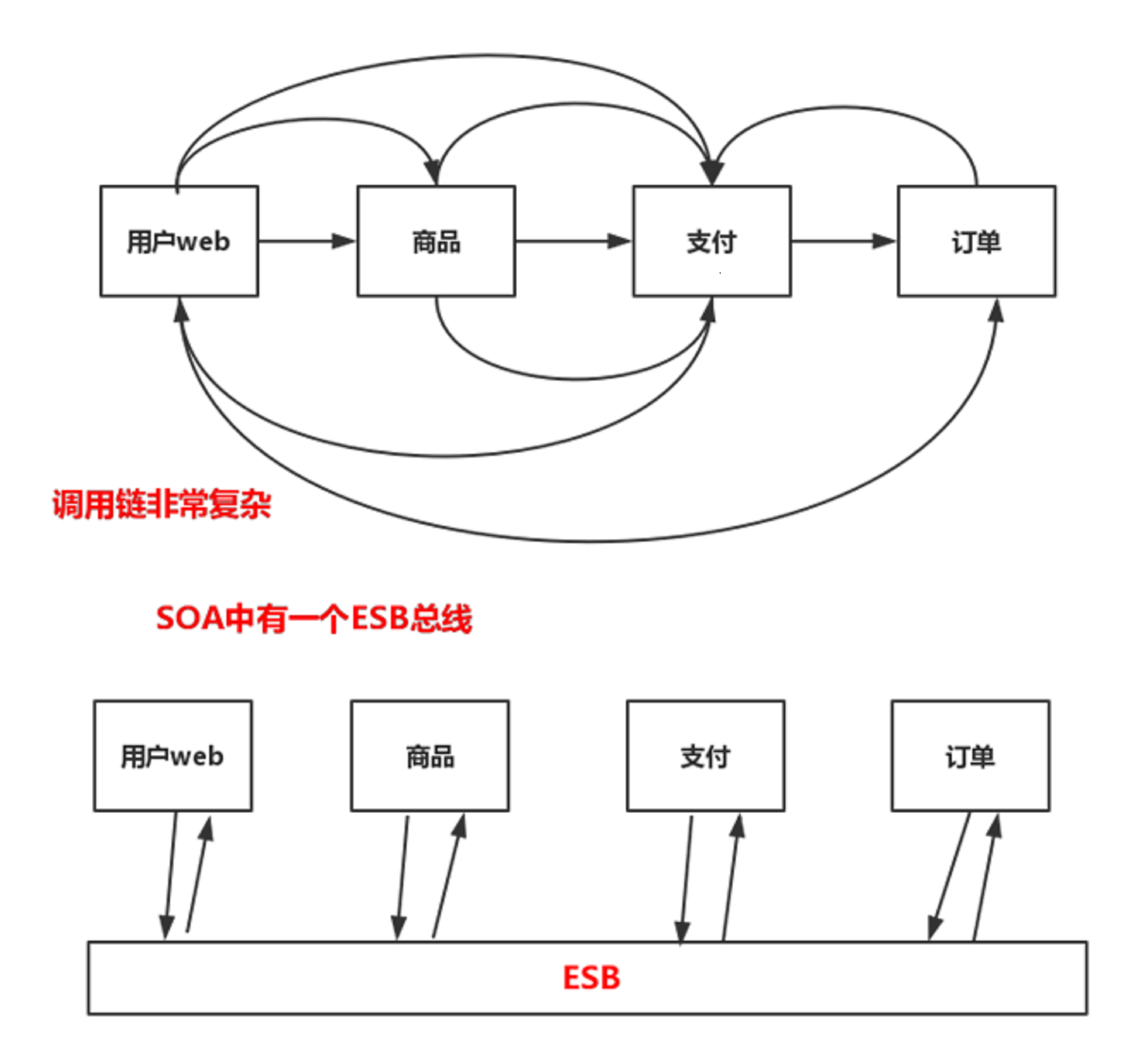
面向服务的变成不是完全的SOA,服务之间相互调用,调用链非常复杂,
为了整理服务之间的调用
SOA:ESB
企业服务总线,
所有的调用全部调用ESB。
帮你屏蔽一些服务的信息,包括不同的数据协议,不同的数据格式,都可以进行统一的约束。
网关
服务层单独做服务。
基于Ngix+lua做网关,
通过网关可以
- 隔离内外网。
- 做接口的处理路由
消息服务总线。
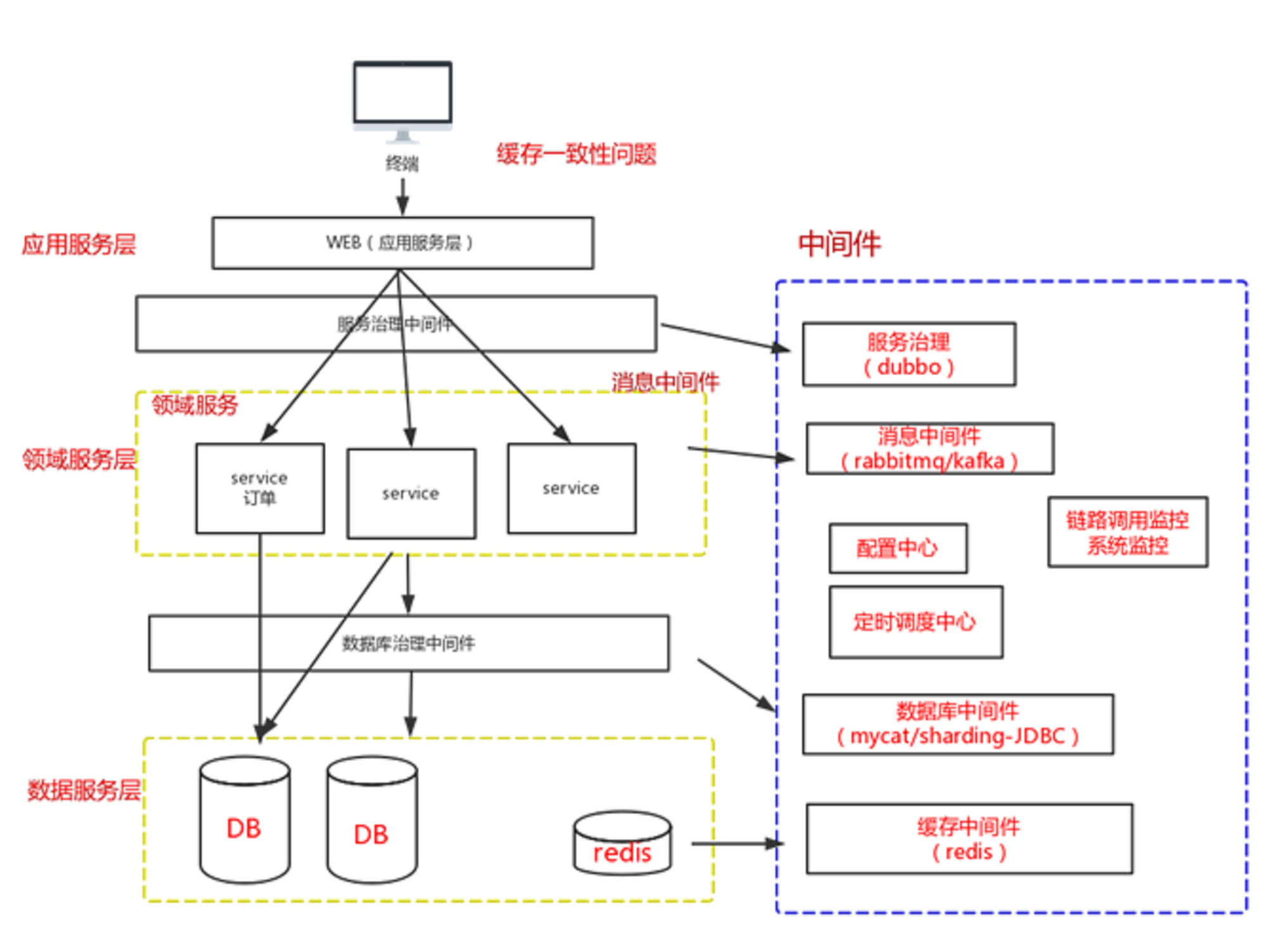
梳理一下架构
终端 >>>> web(应用服务) >>>> (服务治理的中间件) >>>> 领域服务 >>>> (数据库治理中间件) >>>> 数据库
服务治理中间件:dubbo
消息中间件:rabbitmq/kafka
数据库中间件:mycat/charding-jdbc
缓存:redis
配置中心:
定时调度中心:
链路调用监控系统调用
架构的发展不是一蹴而就的。
是慢慢的发展的。
冯诺依曼模型
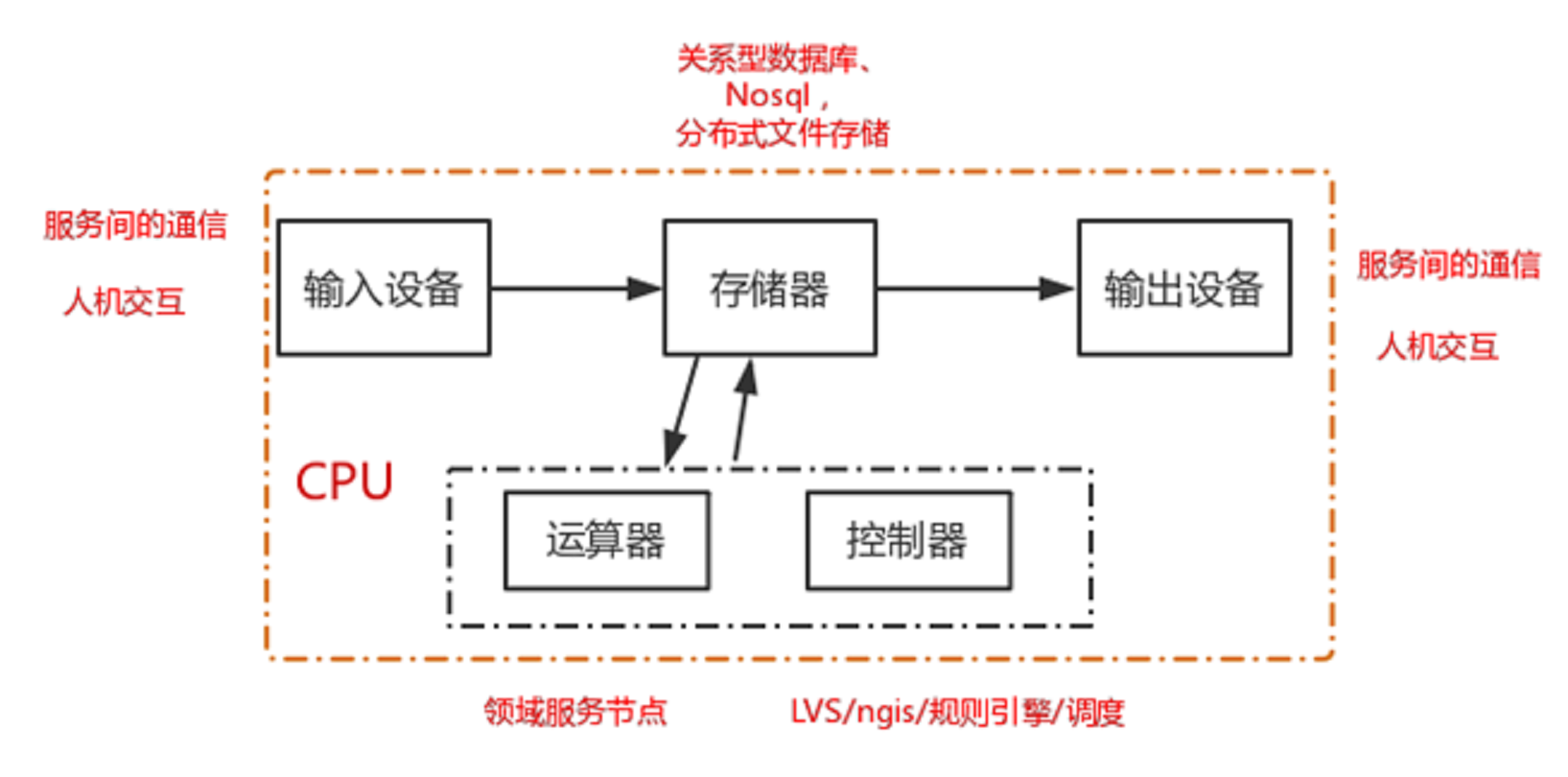
输入设备:(各个节点之间的通讯,服务之间的通讯,人机交互)
存储器:(关系型数据库、Nosql,分布式文件存储)
运算器:(领域服务)
控制器(LVS/ngis/规则引擎/调度)
输出设备(通讯的返回值,用户端的界面展示)
把整个分布式架构可以看做是超级计算机。
浅谈并发
最早的并发,计算机的并发。
如何隔离不同指令
如何进行指令的切换,
进行内存隔离,
进行文件隔离,
然后出现了进程,
进程的调度
共享内存
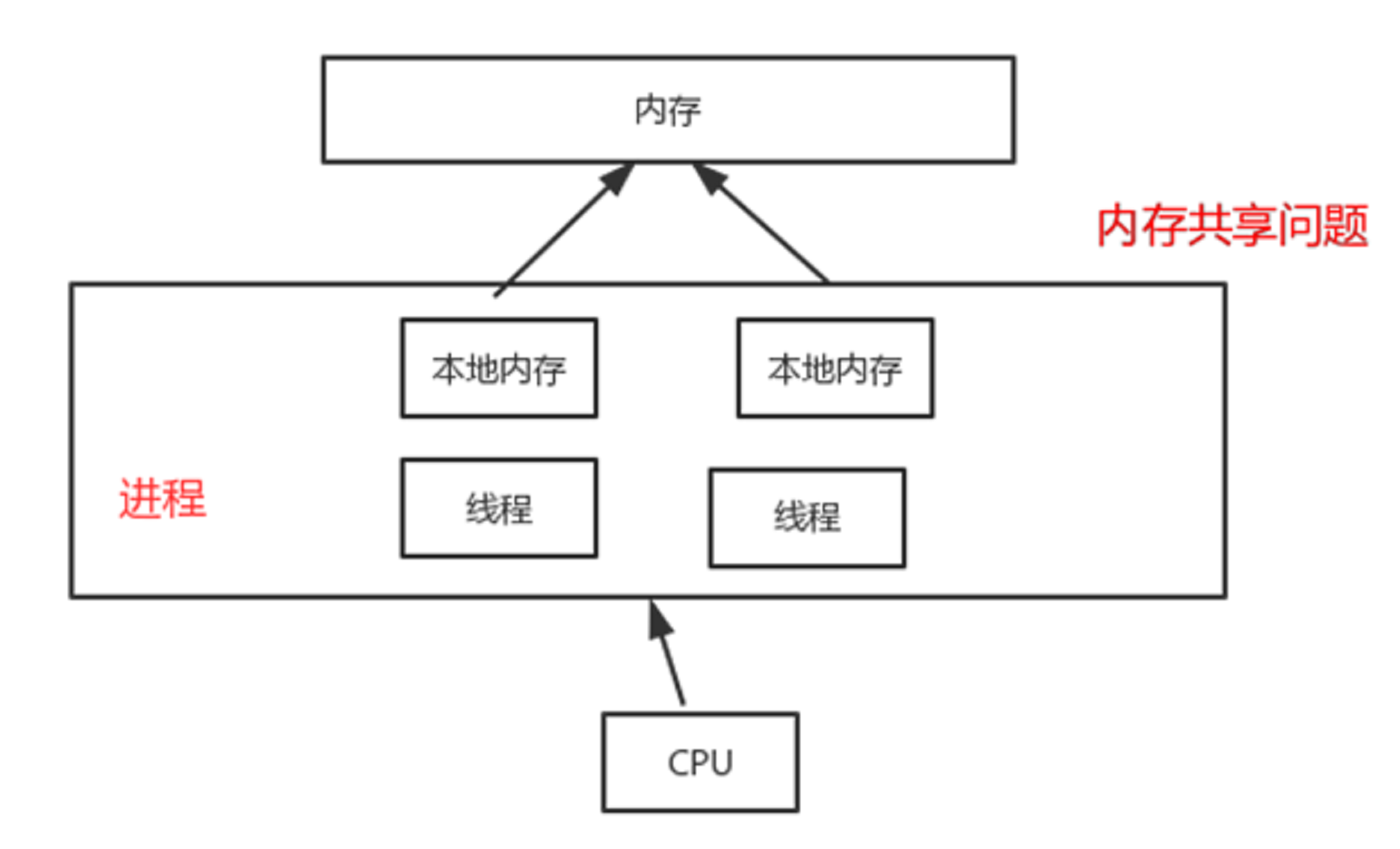
进程需要CPU时间片的切换不能够实现真正意义上的并行。
进程中出现了线程,
线程是CPU调度的最小单元!
线程可以达到真正意义上进程内的一个并行
在进程内达到多个线程的并行。
线程的创建和切换的开销比较小
线程不安全问题。
线程和内存之间会有本地内存,存储变量的缓存
类似于分布式架构缓存一致性的问题。
分布式架构的难点
1. 三态
a. 成功 b. 失败 c. 超时或者未知)
2. 分布式事务
(多个存储节点下的数据库一致性问题)
3. 负载均衡
(入口端的负载,领域服务层的负载、服务发现)
4. 一致性
(CAP)
5. 故障的独立性
(隔离,故障的隔离,单个节点的故障不影响集群的运行)
CAP
BASE
领域驱动
分布式架构的组成因素。
Xsell sftp:一些终端的一些工具。